Mesh RCNNのお気持ちを理解したい
目的
Mesh R CNN について理解する
Lv1. お気持ちの理解
Lv2. どんなNetwork構造
Lv3. loss など詳細な設計
前提
- github はこちら
https://github.com/facebookresearch/meshrcnn
概要
2D image から mesh(3D 形状) を 獲得する手法(下図)
入力から出力までEnd-to-End学習

背景(関連研究)
3D関連の研究が近年盛ん 様々な技術が存在するか関連する代表的なものを簡単に紹介する
2D Object Recognition
単一画像を入力して特定の物体を検出する.Bboxによる矩形の抽出とカテゴリラベルを出力するものが一般的
mask R-CNN ではこれに加えて物体の領域を表すインスタンスセグメンテーションマスクを抽出するSingle-View Shape Prediction
単一画像を3次元再構成する.3Dのpose や既知の形状の向きを推定するものが一般的
Multi-View Shape Prediction
複数カメラによる画像から3次元再構成を行う.mesh R-CNN では扱わないが,この分野の研究は近年盛ん
3D input
3次元画像を入力してsemantic label などを出力するタスク
RGB-D imagesやpoint cloud などを入力するのが一般的
3D dataset
imagenet や COCO datasetにより 2D分野は大幅な発展を遂げた
3D dataset は 2D に比べてアノテーションが困難である問題からいまだ発展途上の領域である
ShapeNet, Pix3D, Pascal3D など様々なものが登場しているが合成データであるものや矩形のみで形状の注釈がないなどデータセット特有の問題なども多い
手法
Lv1.お気持ちの理解
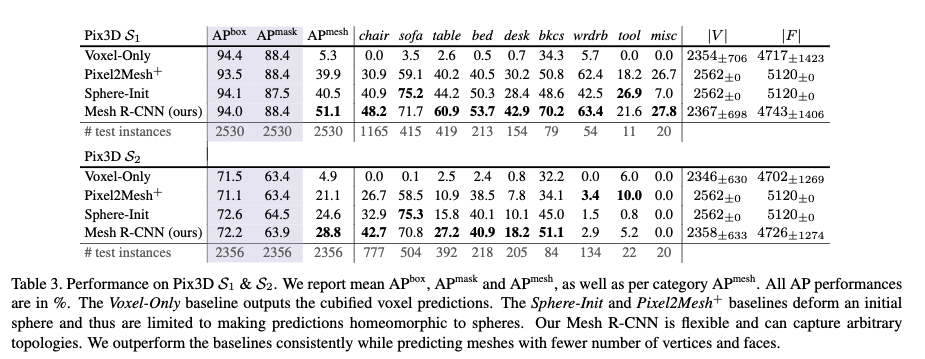
大まかなアーキテクチャは以下図に示すように, 物体の検出 --> 物��体のboxel化 --> meshに変換 --> meshを改良(refinement)
のstep で構成されると思って良い.

Lv2 Networkなども含めて解説
下図に提案システムの詳細な流れを示す.
大まかな流れはLv1 で説明したがもう少し詳細に述べる.
まず,物体検出部分では従来のSoTA model である mask R-CNN を用いている
--> カテゴリラベル, bbox, segmentation mask を出力
backbone は resnet50(pre-trained by imagenet)
3D 形状を予測するために,Voxel Branch と Mesh Refinement Branch を用いる
名前の通りではあるが,
- Boxel Branch .. object の大まかな 3次元ボクセル化を推定し,初期三角mesh に変換
- Mesh Refinement Branch .. グラフ畳み込み層を使用して、この初期メッシュの頂点位置を調整(meshを整える)
と言った役割がある.
-
Voxel Branch
- 各object の形状をボトムアップで予測
- 気持ちとしては,mask R-CNN の mask branch と似たような機能
- 2D 平面の M M --> 3D な G G * G の形状を予測
- Loss については後述(Lv3 にて)
- (補足) 画像と予測値とのピクセル単位の対応関係を維持することは、3Dではカメラから離れるにつれて物体が小さくなるため複雑である.それを回避するためにカメラ特有の固有行列を利用して理想的な形状にする工夫を行なっている
-
Cubify
- Voxel to Mesh
- 目的は,ボクセル予測値を三角形のメッシュに変換する
- ボクセル占有確率と、それを二値化するための閾値を入力
-
Mesh Refinement Branch
- 目的は,粗い形状(voxel化)を滑らかにすること
- 処理の流れは大きく3つで構成(vertex alignment, graph convlution, vertex refinement)
- この3つを繰り返していくことで頂点が更新されていく
- なお,各レイヤーでは各メッシュ頂点の3D位置viと特徴ベクトルfiを持つ
- vertex alignment
- 各メッシュ頂点に対して画像整列された特徴ベクトルを生成
- カメラの固有行列を使用して,各頂点を画像平面に投影
- 特徴マップが与えられると、投影された頂点の位置を示す双線形補間された画像特徴量を計算
- graph convlution
-
メッシュの辺に沿って情報を伝播

-
GCNにより ,局所的なメッシュ領域の情報を集約
-
- vertex refinement

- メッシュ形状が更新され、トポロジーが固定
- Loss については後述(Lv3にて)
Lv3 Loss などの設計
提案システムはどのように最適化されるのかを説明する
-
Voxel Loss
- Voxel Branchは、予測されたボクセル占有確率と真のボクセル占有率との間の2値クロスエントロピーを最小化するように訓練
-
Mesh Loss
- 有限の点集合上で定義された損失関数を使用
- point cloud によるメッシュを、その表面を密にサンプリングすることで表現
- --> 点群の損失を形状の損失に近似
- 大きく3種類のLossを定義
- Chamfer Loss
- point cloud P, Q が与えられた時,以下の式で定義

- 一番近い頂点との距離を計算
- Normal Loss
- 法線up, uq の内積を計算

- 頂点q の接平面状に 頂点p と隣接頂点が存在すると小さくなる
- Edgde Loss

- ある頂点と隣接頂点との距離を計算して正規化する
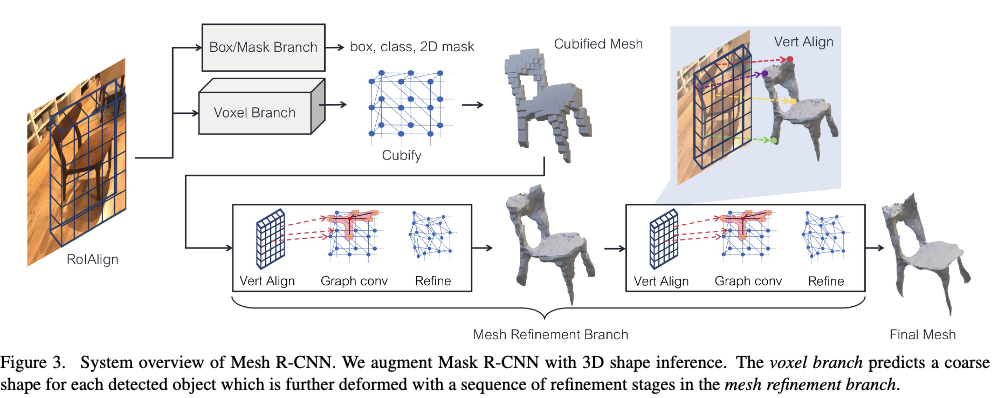
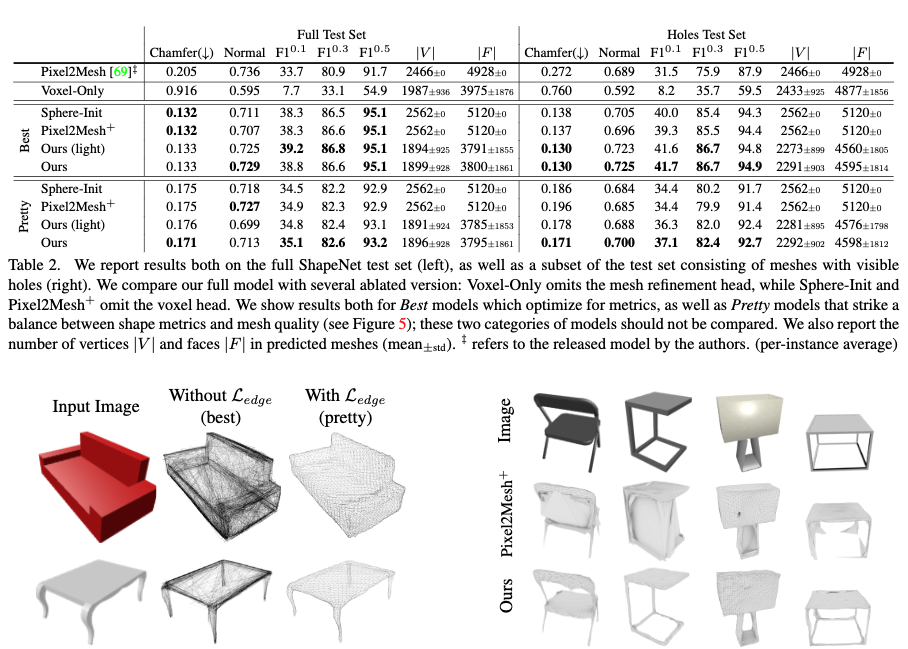
- (補足) Edgde Loss の 有無による形状の比較を以下に示す.なしの方がきれいに生成できているが,不規則なサイズの面と多くの自己交差を持つなどアプリケーションにとって実用的でないことが懸念される
- mesh refinement branch では上記の3つの損失の加重和を最適化する
実験
学習は画像とmesh のペアを用いた教師あり学習
baseline手法
-
N3MR ... 3D の教師なしで微分可能なレンダラーを介してmeshを学習する弱教師あり学習
-
3D-R2N2 ... ボクセルを推定
-
MVD ... ボクセルを推定
-
PSG ... point cloud を推定
-
Pixel2Mesh ... 初期楕円体を変形・細分化してメッシュを推定
-
GEOMetrics ... Pixel2Mesh を 適応的な面細分化で拡張したモデル
なお,boxel_only な手法は 提案手法におけるMesh Refinement Branch を除いたもの
mesh_only な手法は Voxel Branch を除いたものと解釈して比較することが可能である
dataset(2 patterns)
ShapeNet ... mesh予測におけるベンチマークのdataset Pix3D dataset ... 実画像も含んだより難しいdataset
評価手法
予測メッシュと正解メッシュの表面からランダムで一様に1万点をサンプリングする
--> それらの点群における chamfer distance(Lower is better), normal consistency, および様々な距離閾値でのF1-scoreを算出
(precision .. GT内の予測点の割合, recall .. 予測内のGTの割合)
ただし,これらは物体の絶大的な大きさに依存してしまうため,rescaleした上で評価している
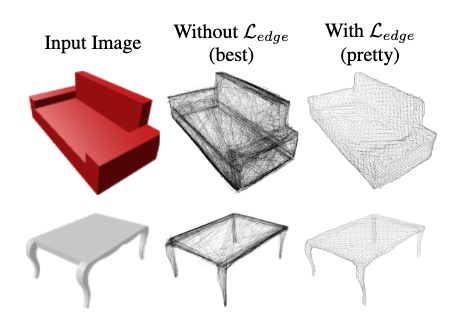
shapenet の評価結果
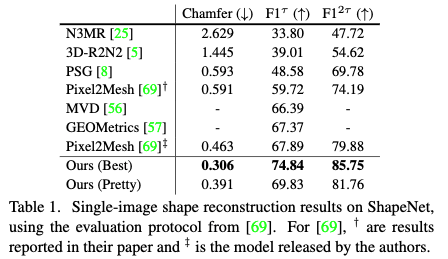
pix3D dataset の評価結果