推薦システムの性能評価に関する研究のまとです。
分類・使い分け
回帰精度
- ユーザー評価の予測に用いられる
- 分類問題としても解けるが序列性があるので、回帰問題として解ける
- 連続値で予測した方が、その後のソートなどに使いやすい
分類精度(二値分類が主)
- ユーザーの評価・購買・閲覧の有無の予測に用いられる
リストの関連性
- 推薦したリストの評価に用いられる
- リストの序列性は考慮されるが、位置が考慮されない古い指標
- 5と推薦したものと、4と推薦したものを評価した場合を考える
- リストでの推薦は、順位が小さいものが相対的に大きく評価されるべきだが、ここで紹介する評価指標は区別がつけられない
- 一つ後で紹介する、『ランク付けされたリストの関連性』では区別できる(前者が悪く、後者が良く出る)
ランク付けされたリストの関連性
- 推薦したリストの評価に用いられる
- リストの序列性・位置が考慮される新しい指標
- リストの序盤の序列の間違いに対し、大きなペナルティを与える
その他
- 推薦システムのリストの評価や、推薦システム全体の評価などに用いられる新しい評価指標
- アイテム・ユーザーのカバー率
- 新しいアイテムの推薦や、推薦するが買われないものにペナルティを与えるなど
- 評価するためのデータの入手が難しいのが課題
回帰精度
MAE(平均絶対誤差)
MAE=N1i=1∑N∣ri^−ri∣
MSE(�平均二乗誤差)
MSE=N1i=1∑N(ri^−ri)2
MAE@k, RMSE@k
- 実際には、ユーザーに表示されるのはモデルの予測値が高い上位数個
- 上位数アイテム(TopK)を対象にMAE, RMSEを算出し、評価する
MAE@k=K1i=1∑KMAEi
分類精度(2値分類が主)
正解率(Acc)
適合率(Precision)と再現率(Recall)、F尺度、ROC
Precision=推薦に含まれる全アイテムの数推薦に含まれる適合アイテムの数
Recall=全ての適合アイテムの数検索結果に含まれる適合アイテムの数
- 適合アイテムを一つ見つければ良い適合アイテム発見タスクでは、適合率
- 推薦誤りの少なさ
- 推薦したアイテム上位n件の内、実際に目的を果たしたものの割合
- 全ての適合アイテムを見つけたい適合アイテム列挙タスクでは、再現率を重視する
- 推薦漏れの少なさ
- 目的を果たしたもののうち、推薦で上位n件に含まれている割合
- 総合的な判断をしたい場合はE-measureやF-measureやROC
F=Precisionα+Recall1−α1
alpha = 0.5の時はF1値
n-points Interpolated Precision
- N点のRecallの平均を取る
- 通常、N=11(recall 0.0, 0.1, 0.2, ..., 0.9, 1.0)
nAIP=N1i∑InterPrecisioni
ROC AUC
AUC(f)=∣D0∣∣D1∣∑t0∈D0∑t1∈D11{f(t0)<f(t1)}
where
- ∣f(t0)<f(t1)∣は、もしf(t0)<f(t1)ならば1、それ以外ならば0を取る
- D0とは負例のサンプル集合
- D1とは精霊のサンプル集合
Hit-rate
- 対象となる単項のデータに対する指標(2値データ向け)
- ユーザーのテストデータから、0でない項目を検索
- アイテムが推薦リストに含まれるか確かめる
- Hit-rateを計算する
hit-rate=nnumhits
numhits: 推薦リストの中に含まれていたアイテムの数
n:全ユーザーのアイテム数
リストの関連性の指標
順位相関(rank correlation)
スピアマン順位相関(Spearman's rank)
rSpearman=1−n(n2−1)6i=1∑n(xi−yi)2
xi: 推薦システムによってランク付されたアイテムiの順位
yi: ユーザーによってランク付されたアイテムiの順位
係数のn(n2−1)6の出し方については、二変量正規分布をいじれば出てくる?
- 正しくランク付けされていれば1
- 数値の大小は関係なし
ケンドールランク(Kendall's rank)
-
二つの項目間の大きさの関係について、ユーザー間の一致を確認する
-
全てのペアがn(n−1)/2個
-
もし、「ユーザーSのAの評価<ユーザーSのBの評価」かつ「ユーザーTのAの評価<ユーザーTのBの評価」ならばP+=1
-
もし、「ユーザーSのAの評価>ユーザーSのBの評価」かつ「ユーザーTのAの評価>ユーザーTのBの評価」ならばP+=1
-
それ以外は、Q+=1として、以下を計算する
τ=21n(n−1)P−Q=21n(n−1)2P−1
- C-:矛盾した選好関係の数
- ユーザーはアイテムAの評価>アイテムBの評価に対し、推薦がアイテムBの評価>アイテムAの評価のようになっている数
- 下の表のD-E
- Cu:推薦とユーザーで同一の選好関係の数
- Ci:推薦とユーザーのランキング間のアイテムペアの優先関係数の合計
NDMP=2Ci2C−+Cu
| Rank | Recommend | User |
|---|
| 1 | A | A |
| 2 | B | B |
| 3 | C | C |
| 4 | D | E |
| 5 | E | D |
上の表のNDMP=2⋅102⋅1+9=2011=0.55
ランク付けされた推薦の評価指標
-
推薦するアイテムの並び方の�良さを評価する
-
最も関連するN個のアイテムを正しい順番で予測しているか
-
適合アイテム発見を目的とする場合、推薦システムには意思決定支援の側面が要求される
- こうした場合は、評価値の大小よりも評価の代償を重視すべき
-
アクティブユーザーの完全なランキングを取得すのは難しい
-
大体ここで問題となっているのは、序列に対する重み
AP(平均適合率)
- ランク付された推薦において、適合アイテムが見つかるたびにその位置での適合率を求め、その算術平均を取った値
AP=R1r=1∑nPrec(r)I(r)
- ここで、Prec(r)は適合率Precision、I(r)はr位が適合文書の場合1、そうでない場合は0を取る関数
- しかし、これでは単純に適合したか否かの二値適合性に基づく評価になる
- 実際の推薦の評価では、部分適合・多値適合性に基づく評価指標を用いる
MAP(Mean Average Precision)
- MAP@k ならば、上位K個のAPの平均を取る
MAP=N1i=1∑NAPi
MRR
- 最初に現れた適合アイテムの順位の逆数の平均をとったもの
- 全対象ユーザーに対して推薦リストを作成
- ユーザーが嗜好する適合アイテムが上位何番目で現れたか調べる
- この順位の逆数を取る(リストに正解が含まれない場合は、逆をとらずに0となる)
- 全ユーザーで平均を取る
MRR=N1i=1∑Ni番目のアイテムの適合順位1
- ランキング下位での順位の差はあまり指標に影響しない
CG(減損しない累積利得)
- DCGの原型
- 正解したアイテムの利得(スコア)を足し合わせていく
CG=r=1∑ng(r)
nDCG(多値適合性に基づく評価指標)
DCG=r=1∑nlog2(r+1)g(r)
-
IDCGは理想的推薦におけ��る減損利得の推薦話
-
正規化されたnDCGは以下のようになる
nDCG=IDCGDCG
ARHR (Average reciprocal hit rank)
ARHR=n1i∈Zl∑pos(i)1
Zl: ユーザーの推薦リスト内のゼロでない項目
pos: アイテムのランキングの位置
Half-life Utility Metric
- アイテムの序列による重要度を半減期パラメータで半減させていく
Ru=j∑2(j−1)/(α−1)max(ru,j−default,0)
r_u,j: ランクj時点での、ユーザーuの実際のアイテムの評価
default: デフォルトの評価値(通常は評価値の平均)
α: 半減期をコントロールするパラメータ
RBP (Rank biased precision)
RBP=(1−p)i=1∑ngipi−1
gi: ランクiの項目の、ユーザーの好みとの��関連性の度合い
p: ランク付されたリストを見ている間のユーザーの持続性をモデル化するパラメータ(通常はクリックログなどから推定)
ERR (Expected reciprocal rank)
- Cascade user model
- 上位に存在する項目の関連性に考慮するモデル
- ユーザーは通常、満足すればそこで検索を終了する
- この場合、検索を終了した時に下にあるものは全てクリックされない
- カスケードモデルの一つ
- rの位置でユーザーが推薦したランキングの閲覧を止める確率の合計を取る
- この確率は、上位の順位に影響される
ERRζ(r)=r=1∑nζ(r)P(user stops at position r)=r1orζ(r)=log2(r+1)1
もしくは
ERRRi=r=1∑nζ(r)i=1∏r−1(1−Ri)Rr=2gmax2g−1
g: ユーザーの好みとの関連性の投球
gmax: スケールで最大等級(1〜5の評価がある時の5)
Q-measure, GAP(Graded Average Precision)
精度面以外での、新しい評価指標
- 探索思考ではないが、ユーザーに役立つ指標
- 探索思考で、ユーザーに役立つ指標
- 推薦がユーザーにとって新しいものか測定する
- セレンディピティメトリクス
- ノベルティメトリクス
- ダイバーシティメトリクス
探索思考ではないが有用な指標
カバレッジ・被覆率(coverage)
- 推薦内容がどの程度のユーザー・アイテムをカバーできているか評価する
- 協調フィ�ルタリングでは、ユーザーから評価がないアイテムについては、予測を行うことができない
- コンテンツベースフィルタリングでは、いくつかの特徴量が不足しているアイテムを予測することはできない
- 予測精度とのトレードオフが存在する
- 牛乳や卵などのほとんどの顧客が購入するものを推薦すれば予測精度は高くなるが、カバレッジは低くなる
カタログカバレッジ
- 利用可能な全アイテムのうち、1回の推薦でどれくらい多くのアイテムを推薦できたか
- 推薦したアイテムの幅広さを示す
Catalogue Coveragewhere SaSr=∣Sa∣∣Sr∣: アイテム全て: 推薦できるアイテム
- 推薦の範囲を適合アイテムのみに絞った適合カタログカバレッジ
Weighted Catalogue Coverage=∣Sa��∣∣Sr∩Ss∣
ユーザーカバレッジ
- 全対象ユーザーのうち、直近1回の推薦のうち、どれほど多くのユーザーに対して推薦できたかを示す
Prediction Coveragewhere SpSu=∣Su∣∣Sp∣: 少なくとも1つのアイテムは推薦システムにより推薦できたユーザー: 全てのユーザー
学習率
- ユーザーの嗜好が変化した後、どれほど早く推薦システムが適切な推薦を提供できるか
- コールドスタート問題に関連する
- システムが素早く適切な推薦を行えないと、ユーザーの満足度は減少する
- 嗜好が変わった��あとの時間
- ユーザーが推薦受けて始めてから、精度を監視し続ける必要がある
確信度
- 推薦にどれほどの確信を持っているか
- 推薦システムを作成するために、どれほどの数のユーザーやアイテムを使っているか計算する
- 協調フィルタリング時に予測で用いるK-NNの類似性を計算する
- 類似性が低い時、K-NNの距離が遠くなるので、それを監視する?
信頼性
- ユーザーの推薦システムへの信頼
- 推薦システムは、ユーザーの嗜好と関心を予測する能力があることを示さなければならない
- ユーザーがよく知っているアイテムを表示しないと、(信頼を?)得るのが困難
- 推薦システムを信頼できなければ、ユーザーは推薦システムを使わなくなる
- 推薦結果が良ければ信頼が増す
- ユーザーにオンライン評価で直接尋ねる
- ユーザーの使用頻度で推定する
探索思考の指標
-
似た商品ばかり推薦していると、ユーザーは推薦に飽きる
-
既知の商品を推薦されても、意思決定の手助けにはならない
-
評価対象:ユーザーセット、アイテムセット、アイテムのペアなど
-
必要なデータ:評価行列(ユーザー*アイテム)、オンとロジー(アイテムカテゴリ)、他の新規性・セレンディピティに関するデータセット
注意点
- 目新しさだけを推奨すると、ユーザーの満足度は低下する
- ユーザーは一般的に、既知のものを好む
- 総合的に評価すると、新規性は利用者の満足度を下げる
- 斬新なアイテムを推薦する際には注意が必要
- 推薦システムでのユーザーの経験を考慮する
- 事前に、推薦システムの新奇性を説明する
- おすすめの新奇項目をそれぞれ説明する
セレンディピティ(Serendipity)
- 推薦がユーザーに驚きを与えるか否か
- (ユーザーがアイテムを自身では検索できない)
- 特定の�アイテムを推薦られた時の驚き
- 他のシステムを利用して計算する?
予想外さ
EXEXPwhere siLirel(si)P(si)prim(si)=∣Li∣1i=1∑∣Li∣max(P(si)−prim(si),0)⋅rel(si): i番目のアイテム: 評価済みの推薦リスト: ユーザーのアイテムsiにたいする評価: ターゲットシステムで予測された評価: プリミティブシステムで予測された評価
UNEXPSRDP=PMRS=N∣UNEXP∩USEFUL∣
where
RSPMUNEXPUSEFUL: 推薦システムによるアイテムの集合: Primitiveシステムによるアイテムの集合: 予想外のアイテムの集合: 有用なアイテムの集合
エントロピーペースの多様性
- ある推薦システムによるアイテム群は、他の推薦システムも推薦しているかどうか
diva,vpu,iwhere AaLa,uRuδ=−i∈La,u∩Ru∑pu,ilogpu,i=∣A∣∑a∈Aδ(a,u,i): 推薦した集合: Targetシステムの評価: ユーザーuのために推薦システムaにより提供された推薦リスト: ユーザーuに関連するアイテム: 1 if i∈La,u∩Ru and 0 otherwise
ノベルティ(Novelty)
-
推薦されたアイテムがユーザーにとって未知であるか否か
-
Discovery ratio, Presicion of novelty, Item novelty, Temporal novelty, Novelty based on HLU, Long tail metric, Generalized novelty model, Unexpectedness, Entropy-based diversity, Unserendipity, HLU of serendipity
測り方
発見率
- 推薦リ�ストの中に、どれだけユーザーが知らないアイテムがあるか
Discoverywhere DiLi=∣Li∣∣Di∩Li∣: ユーザーiが知らないアイテムのリスト: ユーザーiに対する推薦リスト
ノベルテ�ィの精度
Precision(novelty)Recall(novelty)where CiLi=∣Li∣∣Ci∩Li∣=∣Ci∣∣Ci∩Li∣: ユーザーiが知らないかつ、好むアイテムのリスト: ユーザーiに対する推薦リスト
アイテムノベルティ
Novitem(i)where ∣L∣d(i,j)Div()=N(Div(L)−Div(L−{i}))=N−11j∈L∑d(i,j)=N: アイテム間の距離を測る関数: 推薦リストの多様性を測る関数
テンポラリーノベルティ
- 過去の推薦リストとは異なる推薦を行なっているかを測定する
Novtmp(Li)where Spast=∣Li∣∣{x∈Li∣x∈/Spast}∣=j=1⋃i−1Lj
半減期ベースのノベルティ
- あるアイテムのレーティングの、通常のレーティングからのゲインを、パラメータを元に減少させていく
- 推薦しているが買われないアイテムは、評価を割り引いていく
- 半減期評価関数
Ruwhere ru,jdefaultα=j∑2(j−1)/(α−1)max(ru,j−default,0): ユーザuがjと評価したアイテム: デフォルトの評価値(通常は平均値): 半減期パラメータ
f(i)NHLUuwhere nni=log2(nin)=i∑Nf(i)2(i−1)/(α−1)max(ru,i−default,0): ユーザー数: アイテムiを評価したユーザー数
ロングテールに基づくノベルティ
- 項目を人気に合わせて3つのカテゴリー(HEAD, MID, TAIL)に合わせる
- 上位N個の推薦から、アイテムaiとajを抽出する
- 斬新なアイテムを推薦する能力を、以下の評価マトリクスで評価する
| ai→aj | HEAD | MID | TAIL |
|---|
| HEAD | 45% | 55% | 0% |
| MID | 5% | 70% | 25% |
| TAIL | 0% | 15% | 85% |
- もし、HEAD→HEADが大きければ、ノベルティは低い
- 人気アイテムが入れ替わっているかどうかの指標?
多様性(Diversity)
-
様々なタイプのアイテムをユーザーに推薦できるかどうか
-
Aggregate diversity, Inter-user diversity, List personalization metric, Gini codfficient, Temporal diversity, Intra-list similarity, Subtopic retrieval, MMR, alpha-nDCG
Aggregate diversity
Aggdiv=u∈U⋃Lu
where
ULu: ユーザーの集合: ユーザーuに推薦したアイテムのリスト
- 分母に全アイテム集合をとることで、全体のアイテムのうちどれだけユーザーに推薦できたかを測っている研究も存在
- アイテムの種類→サブカテゴリ・サブトピックなどにすることで、カテゴリ・トピックの多様性を図ることもできる(Subtopic retrieval metric)
Inter-user diversity
- ユーザー間の多様性
- ユーザー間で異なる推薦システムを提供する仕組み
- 推薦システムがどれほどユーザー個人個人に合わせられているか(IUD)
du,vIUDwhere UNNULu=1−N∣Lu∩Lv∣=NU1u,v∈U∑du,v: ユーザー集合=∣Lu∣=∣Lv∣: Uの中の2つのペア数: ユーザーuに推薦したアイテムリスト
List personalization metric
pbIbPer(Li)where pbIbPer(Li)Ub=UUb=log2(Ub∣U∣)=∣Li∣∑bj∈Lilog∣Ub∣∣U∣: アイテムbがユーザーにより選択される確率: アイテムbの自己エントロピー: アイテムの個人化の度合い: アイテムbを選択したユーザーの数
Gini係数
- 所得のアンバランスさの指標などに使われる
- アイテムの推薦頻度がどれだけ偏っているか
- x軸:推薦リスト内の合計頻度の高い順に並べられたx%�の割合
- y軸:リスト内の項目のx%の合計頻度
Gwhere AB=A+BB: グラフを書いた時、45°の線と曲線の間の面積: それ以外の面積(曲線の下の面積)
時間的多様性
- 時刻が違うと、システムが出力する項目が異なる場合の測定
divtmp(L1,L2,N)=N∣{x∈L2∣x∈/L1}∣
where N=∣L1∣=∣L2∣
推薦リスト内の多様性
- 推薦リストの内容に応じた多様性
- 2つのアイテムの類似度で計算される
Diversity=l∈Li,m∈Li∑similarity(l,m)1
where Li: ユーザーiに推薦したアイテムリスト
ILS(Li)=(2∣Li∣)∑bk∈Li∑be∈Li,bk=besimilarity(bk,be)
MMR(Maximal marginal relevance)
- 本来は検索結果に文書を選択するための項目選択法
- この考え方を、推薦結果のリストの評価に利用する
MMRList=di∈L∑(α⋅rel(di)−(1−α)dj∈Li−1maxsim(di,dj))
where
LdirelLi−1: 推薦リスト: リスト内のアイテム: そのアイテムをユーザーが好むか否か: j番目までの推薦リスト
推薦システムの評価指標の注意点など
- APやnDCGにより、特定のユーザーに対するランク付された推薦を評価できる
- システムを評価する場合、複数ユーザーに対する平均的な良さを評価する必要がある
MAP
MAP=N1i=1∑NAPi
- できるだけ多くのユーザーにある程度適合する推薦を提示したい場合、MAPだけでは不十分
GMAP(幾何平均を用いたMAP)
GMAP=nn∏APn
便宜上変形すると、以下の形になる
ただし、εは非常に小さい値(10^(-5)程度)
GMAP=exp(N1i=1∑Nln(APi+ϵ))−ϵ
一部のユーザーへの推薦で、適合アイテムが一つもない場合、GMAPはMAPより低く評価する
- 上位10位までのように測定長が短い場合、MAPやGMAPの値は不安定なものになりやすい
infAP(inferred Average Precision)
- 不完全性なテストコレクションから真の平均適合率を推定する
施策に対する評価指標
- アイテムの特定項目分布
- プッシュしたいカテゴリが存在する場合などは、提供されたアイテムの特定項目に関する分布を基に評価を行うことができる
- NGアイテムの出現頻度
- 目的のアイテム・カテゴリ等への遷移率
- アイテムごとのPV数のジニ係数
- システムによるアイテムビューが偏らないような仕組みを導入した際に、偏りが是正されるか計測
interleaving
2017年での企業の状況(RecSys 2017 Conference)
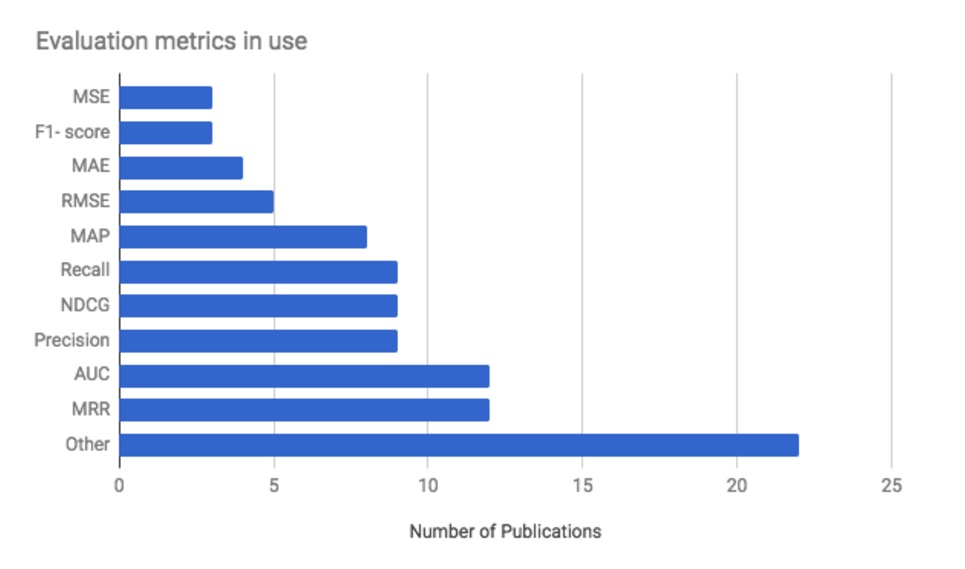
- 推薦システムの学会で、2017年現在での企業で使われている指標は、多い順に以下の通り
- MRR(序列を考慮した推薦リスト指標・重みは序列の逆比)
- AUC(分類問題)
- Precision(適合アイテム1つ発見)
- nDCG(序列を考慮した推薦リスト指標・重みを調整可能)
- Recall(適合アイテム全列挙)
- 論文では探索重視の評価指標などは提案されてはいるが、実環境では答えのデータが取得しにくく、現場ではまだあまり使われていない。
- MRRやnDCGは、比較的新しい手法だがよく使われている。
参考文献