Use Cases for Learning-based Recommendation Systems
I had to build a recommendation system, so I did some research on use cases as part of the preparation. Netflix really is incredible.
Types of Recommendation Systems
- With / without personalization
- When personalizing, two main types of data are used: content information from user profiles and item genres, and user behavior history
- Start with recommendations from user profiles, then switch to behavior history-based recommendations once data accumulates
- The latter tends to better reflect user preferences
Popularity Ranking / Newest First
Advantages
- High effectiveness relative to low implementation cost
- Effective when item turnover is high
Disadvantages
- When item turnover is low, the same items keep being displayed
- In such cases, use trending/rising rankings as a workaround?
Industries
- Almost all services
Browsing (Purchase) History Display
Advantages
- High effectiveness relative to low implementation cost
- Effective when users frequently re-browse (re-purchase) items they have viewed (purchased) before
Disadvantages
- Not very useful for infrequently purchased items (electronics, etc.)
- Consumables must be displayed at the right time to be effective
Industries
- Video, music sites
Similar Item Display
Advantages
- Increases user browsing and helps them find desired items
- Computes content similarity based on item descriptions, category information, and other content information + user behavior history
- The latter captures item atmosphere and concept better than the former
Disadvantages
- For products where one is sufficient, post-purchase display is not very meaningful
- Focusing solely on click-through rate may increase noisy browsing history from interesting or unusual products that do not lead to purchases
Industries
- E-commerce sites
Direct Recommendations to Users
- Recommendations based on user behavior history and profile
- Often displays items similar to the last viewed/purchased item
- The similar item display system above can be used
Case Studies from Other Companies
Netflix
- Over 80% of watched content comes through recommendations
- Originally an online DVD rental company
Recommendation System Features
Information Used
-
Content information -> User behavior information -> User ratings (5-level) -> User ratings (2-level)
-
Content information (genre, cast, director, etc.)
-
Easy to implement
- Recommendations lacked persuasiveness (were not appropriate)
-
-
User behavior information (which titles a user rented together)
-
Better performance than content information
-
Actual recommendation quality could not be gauged
- Could not handle cases where a rental was a "miss"
-
-
User ratings (5-level)
-
Could make recommendations reflecting content preferences
-
(Individual bias in user rating methods)
-
(Difficult to incorporate into the system / solve with regression?)
-
-
User ratings (2-level)
-
Recommendations reflecting content preferences
-
Easy to display as "XX% likely to enjoy"
-
Easy to incorporate into the system
-
-
Cold Start Problem
- Use popularity ranking -> Ask users to select favorite titles during registration + use popularity ranking if they skip
Display Method
- Rows represent recommendation categories (new releases, genres, popular titles, etc.), columns represent recommendation rank
- Makes it easier for users to explore content
- Scroll vertically to find interesting genres, scroll horizontally to find interesting titles
- Makes it easier for users to explore content
- Filter recommendation content based on previously watched titles and existing ratings

Other Topics
Trends
- Deep Learning
- Causality
- Bandits & Reinforcement Learning
- Fairness
- Experience personalization
Deep Learning
- Became widespread in recommendation systems around 2017
- Previously collaborative filtering and matrix factorization (MF) were used
- Simply feeding user information and item matrices into deep learning does not always work, but when done well, accuracy improves
- Use user behavior history (transition information)
- Use large amounts of information
- Accuracy improved when carefully designed with discrete time information (day of week, hourly history) + continuous time information (recent behavior history)
Causality
- "Watched because it looked interesting" vs. "Watched because it was recommended"
- Debiasing Recommendations
Bandits & Reinforcement Learning
- Interest in new content is uncertain and user tendencies change, so recommendations need exploration
- Detailed design in Slide 36P~
Fairness
- Are recommendations biased toward certain genres?
- By applying weighting coefficients per genre, various genres can be recommended
Experience Personalization
- Algorithm level, UX level, behavior level
References
- https://note.com/masa_kazama/n/n0f70dcc0989e
- https://netflixtechblog.com/learning-a-personalized-homepage-aa8ec670359a
- https://www.slideshare.net/justinbasilico/recent-trends-in-personalization-a-netflix-perspective
Airbnb
- Accommodation and vacation rental service
- The following is from a February 2019 article
- Has a two-stage service: accommodation plans and experience plans at the destination

Recommendation System Features
Models (3 stages from introduction to present)
- Adjust model complexity according to data volume
1. Initial Model (Strong Baseline)
-
Few recommendation candidates, data collection just started
-
Data Collection
- Rank randomly every day to collect data
- Collect logs of users who booked to rank candidates
-
Labeling
- Collected 50,000 training examples labeled as booked (positive) and clicked but not booked (negative)
-
Features
- 25 dimensions: experience plan details/data, reviews, number of bookings, click-through rate, etc.
- When the service is growing rapidly, convert counts to ratios to prevent model breakdown
- Since it is experience plan information -> prediction, the same ranking is provided to all users (users create subsets by setting search criteria / rankings are updated daily)
-
Model
- GBDT binary classification
- No feature scaling required, handles missing values directly
-
Evaluation
- Rank according to model scores and evaluate with AUC and nDCG
-
Model Analysis
- Observe how scoring changes when all values except one feature are fixed
- (Shapley value-based feature contribution calculation?)
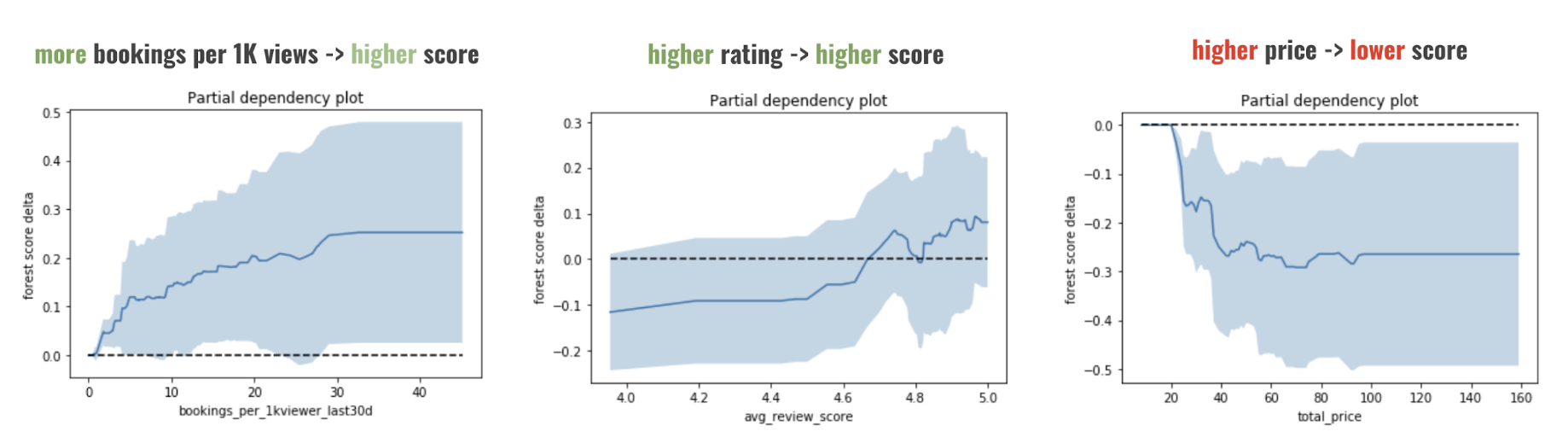
- Observe how scoring changes when all values except one feature are fixed
- (Shapley value-based feature contribution calculation?)
-
Validation
- A/B test comparing with rule-based random ranking
- +13% in bookings
2. Personalization Model
- Goal: Quickly capture user interests and place appropriate content at the top of search results
- Two different types of personalization:
- Information from booked accommodation plans
- Since accommodation plan booking -> experience plan booking, accommodation plan information can be used
- User click information
- Interest level in specific categories over the past 15 days (click rate, weighted sum of categories from clicked plans, days since last click, etc.)
- User available time slots (proportion of time slots from plans the user clicked)
- Information from booked accommodation plans
- Ranking Model Training
- 50 ranking features from 250k labeled samples
- Care taken to avoid leakage
- Time-series-preserving features
- Data from users who viewed only one plan (= high probability of booking that plan) is not used
- Train two models: one with personalization features for logged-in users, and one without personalization for logged-out traffic data
- Personalization features depend on data; useless without it
- Ranking Model Testing
- A/B test: stage 1 vs. stage 2
- +7.9% improvement
- Implementation Details
- Created a table keyed by UserID; logged-out users have UserID := 0
- All rankings computed offline daily, but limited to the most active 1 million users due to weight
- Up to about 1 day of delay
- This model was used to measure the gain of the personalized model for transitioning to Stage 3
3. Online Scoring
- Features
- In addition to previous ones, also uses search plan settings (query feature information), browser information (language, country) for scoring
- Ranking Model
- Over 2 million labeled data points
- 90 features
- Two GBDT models
- Model for logged-in users using experience plan features, query features, and user features
- Model for logged-out users using experience plan features, query features, and traffic data
- Advantages of Online Scoring Model
- No need to pre-compute personalized rankings; can recommend for many use cases
- Ranking Model Testing
- A/B test: stage 2 vs. stage 3, +5.1%
- Implementation Details
- Consists of the following 3 infrastructure components:
- Obtain model inputs from various sources in real time
- Deploy the model to production
- Perform model scoring
- Storage methods for features varied by infrastructure component
- Consists of the following 3 infrastructure components:
4. Using Business Rules
- Improve service quality
- Changed the objective function from (+1=booking, -1=clicked but not booked) to learning with weights (low rating=low score, high rating=high score)
- A/B test confirmed improvement in booking quality
- Cold Start Problem
- Discover new users and recommend via ranking
- Enhance diversity within Top 8 results
- Effective when traffic information is scarce
- When users visit the web page but do not search
- Considered to have a different purpose; selected Top 18 by ranking score, re-ranked by click rate, which proved effective
Ranking Monitoring and Explanation
-
Track general trends of the ranking algorithm and confirm they are desirable trends - Cheap plan != great plan, but cheap plans were being recommended more easily - Removed "price" from the model features, with no issues
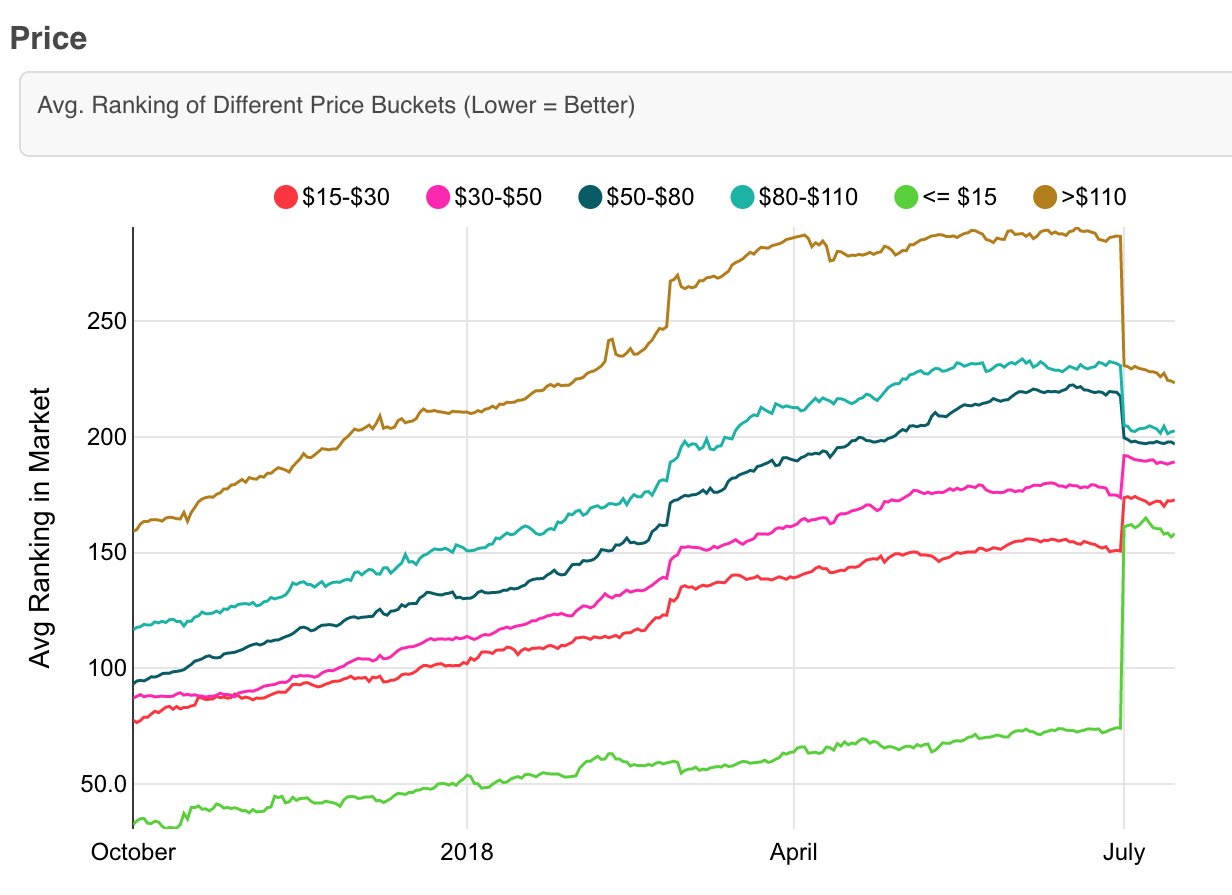
-
Track the rank of a specific experience plan in the market and the features used in the ML model
-
Ranking trends for specific groups (e.g., 5-star experience plans)
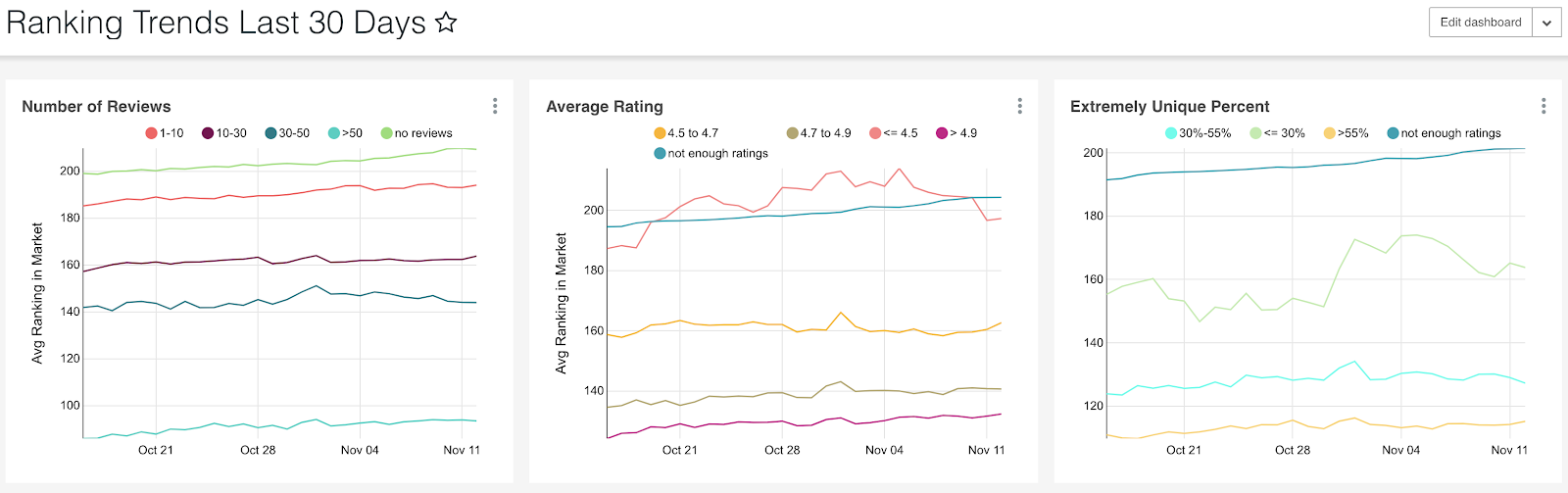
-
Particularly useful for market managers to send appropriate feedback to hosts
Existing Challenges
- Loss Function
- Pairwise loss
- Labeling
- Regression based on score functions rather than 0 or 1
- Real-time Signals
- Minute-level history rather than daily
- Addressing positioning bias in training data
- Testing various models beyond GBDT
Summary

References
Gunosy
- Specifically about the news app
- Over 10,000 new articles per day
- Needs fast and stable recommendations from a large volume of articles + behavior logs
Recommendation System Features (News-specific)
- News value decays over time
- By the time behavior logs accumulate, the news value is low
- Users' interest cycles change rapidly
- Word match alone does not guarantee quality
- "XX passed away", "Earthquake in XX prefecture", "XX won at YY"
Recommendation System Features
Model (Custom Matching-based Model)
- News articles -> Embedding in vector space
- Average of vectors from the M most recently viewed news articles -> User vector
- Each time a new article is clicked, remove the oldest article, add the new article's vector, and recompute the average
- Sort and recommend articles by density around the user's vector as a score
- This is the core and the detailed scoring is proprietary
- Scores are configured to decay over time
- Previously viewed articles are also decayed
Known Issues
Functional Verification
- Limited data in development environments
- Difficult to verify list comprehensiveness due to personalization
Offline Experiments
- A/B testing for parameter tuning is difficult
- Does not necessarily match online experiments
Handling Transitions
- Tends to rely on click-based recommendations, but would also like to recommend based on article viewing transitions
- Practical implementation requires careful data structure design
References
Instagram
- A system involving Facebook AI
Recommendation System Features
User Account Embedding
-
Uses content information liked by user accounts to embed account IDs like Word2vec
-
Distance is calculated using cosine distance or dot product
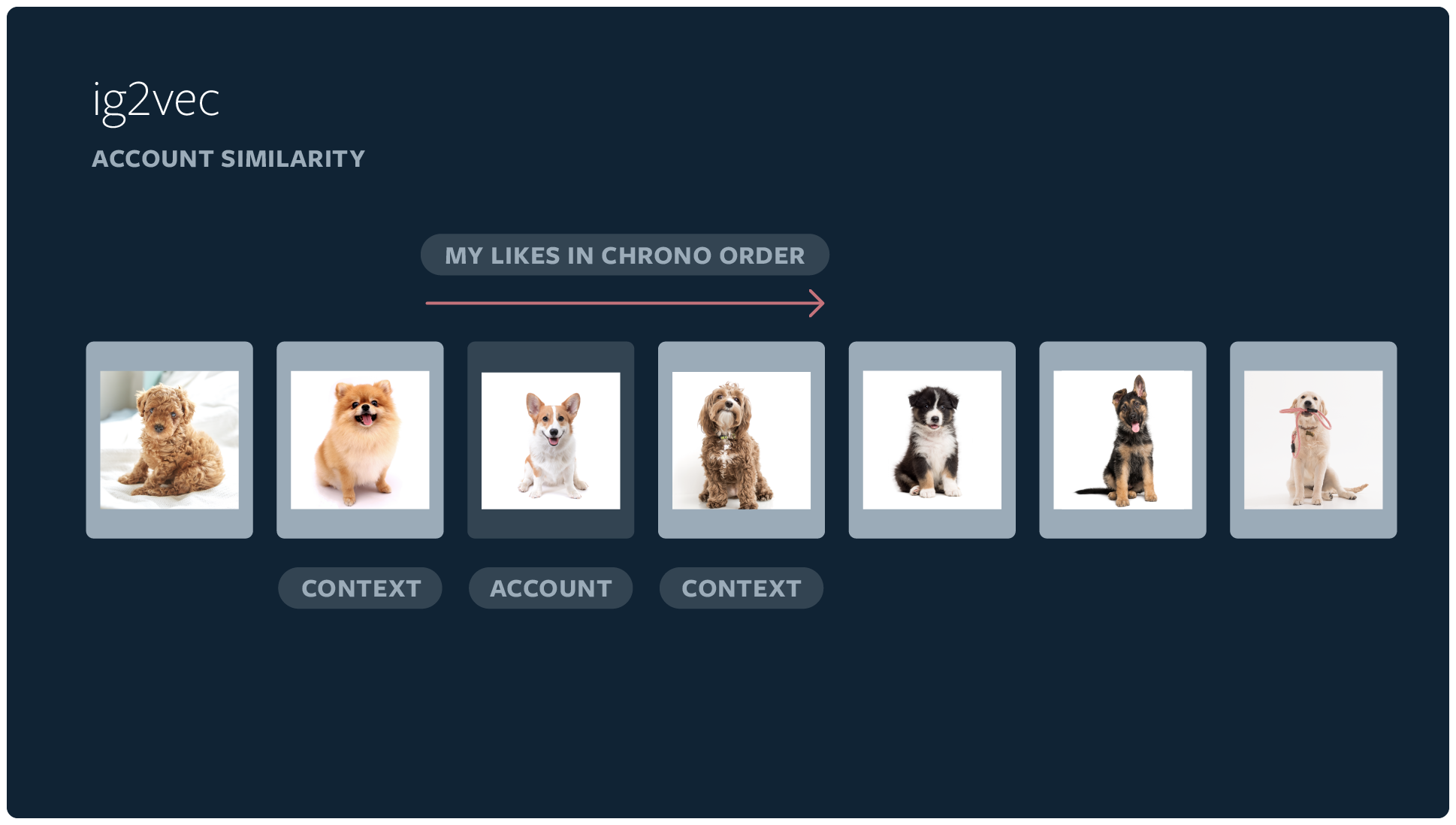
-
Uses FAISS, developed by Facebook, for nearest neighbor search
-
Trains a classifier to predict the topic set of an account using this embedding
- Narrows down the content presented to the account
Ranking Model
- The ranking model uses a small model distilled (approximated) from a large model
- Trained to optimize nDCG loss
Candidate Generation
- Finds similar accounts using embeddings of accounts the user liked or saved, then finds media posted/engaged by those accounts
- Identifies thousands of candidates and narrows down to 500 for the next stage
Ranking Candidates
-
A small model approximating two other models narrows from 500 to 150 candidates using minimal features
-
A lightweight NN using full dense features narrows from 150 to 50 candidates
-
A NN using all features narrows to 25 candidates
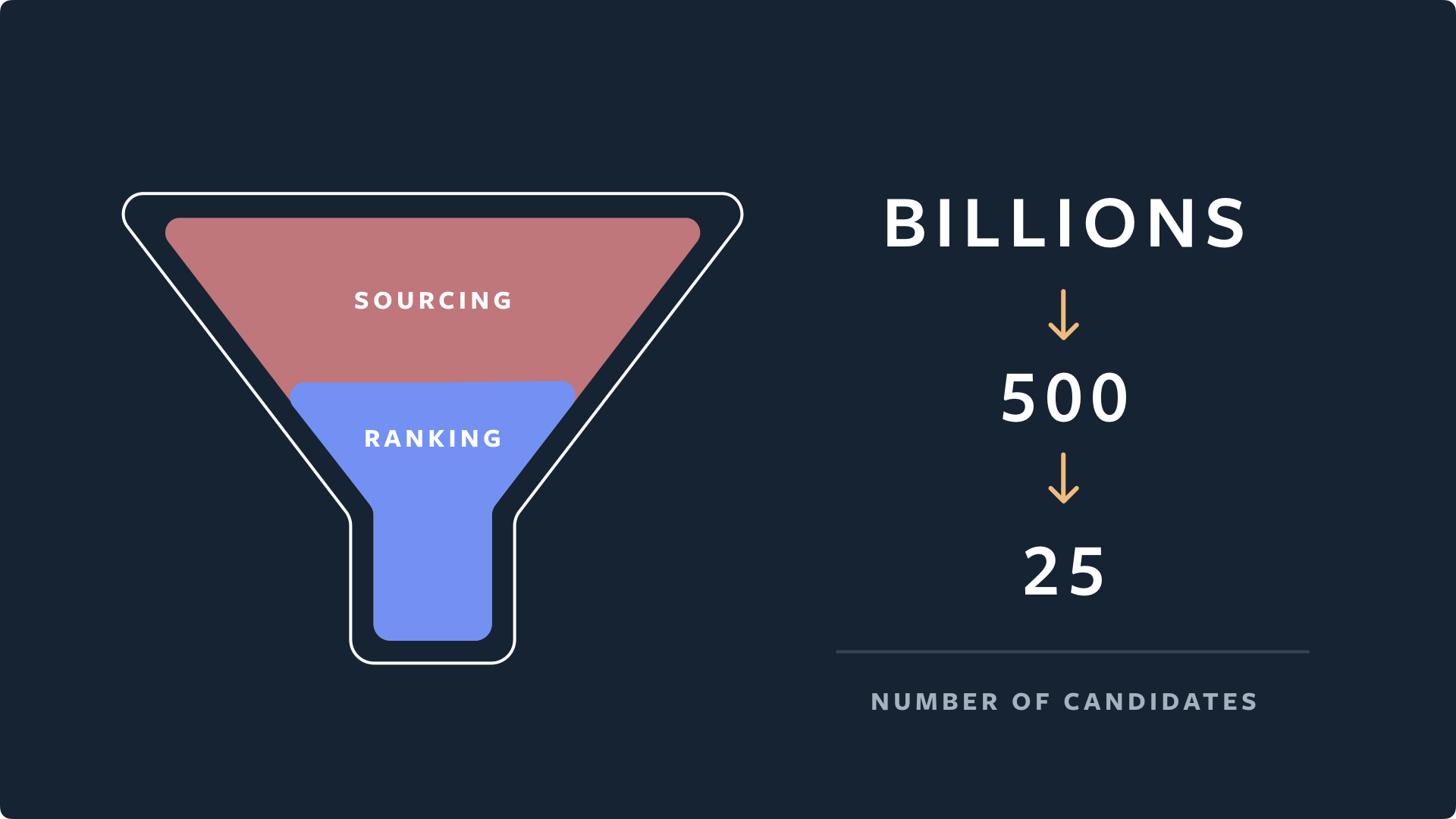
-
The NN predicts positive and negative behaviors such as liking, saving, and reducing display, and ultimately determines signal importance through a weighted linear combination for content
- Produces the ranking
-
Simple heuristic rules were added to increase diversity
- Penalize posts from the same author by lowering their rank
- Prevent multiple posts from the same author from appearing
References
Spotify
- Music has far more items than movies
- Content duration is short
- Replay frequency is high
Recommendation System Features
Model (Multi-Armed Bandit)
- Uses the multi-armed bandit framework to balance exploration and exploitation
- Exploitation: Recommend based on previously selected music and podcasts
- Identify and deliver favorite content
- Exploration: Reveal uncertain user responses to unknown content
- Exploitation: Recommend based on previously selected music and podcasts
- Training and inference are completed within the algorithm without requiring A/B tests or randomized experiments
System Development and Monitoring
- Unified model/validation libraries with TensorFlow
- Accelerated model development with Kubeflow
- Alerts at specific thresholds
References
Cookpad
- Recipe recommendation, push notifications, recipe author follow recommendations, search keywords, etc.
Recommendation System (Development) Features
KPI Design Aligned with Business Model
- E-commerce sites: revenue, number of purchasers; Ad sites: impressions, click rate, etc. as goal design
- Cookpad-specific considerations
Difficulty of Integrating Recommendation Systems into Existing Systems
- Ease of data acquisition and maintenance
- Large impact = large scope when negative impact occurs
References
Retty
- Restaurant (reviews, reservations, etc.) web and app service
- Pseudo-restaurants, popular restaurant recommendations, extraction of useful reviews and photos
Recommendation System Features
Model (Algorithm Selection)
- Similar restaurants -> Content-based filtering
- Popular restaurants -> Popularity ranking
- Based on past trends -> (Item) Collaborative filtering
- Random recommendations -> Mixed in at a random proportion for evaluation
Presented Information
- Display recommendation reasons for items
- Eliminate distrust (not operator-driven ads)
- Appeal selling points (make appeal points clear)
- Introduce comparison elements (make item comparison easier)
Exploration
- Use of bandit algorithms
- Maximize cumulative reward while probabilistically presenting items
- Use ElasticNet to avoid overfitting
References
ZOZO
- Recommending similar items from images sent by users
Recommendation System Features
Model
- Image -> Object detection -> 512-dimensional feature vector -> Approximate nearest neighbor search
References
Mercari
- Image search
Recommendation System Features
- Image -> Feature vectorization -> Approximate nearest neighbor search
Others
- BigQuery ML
- Recommendation AI