目的
テーブルデータをコンペで扱う際に覚えておきたいポイントや学習中に得られた知見などをまとめる.
また, テーブルデータとテキストデータ, テーブルデータと画像データの違いや共通点, ポイントも記述する.
テーブルデータの知見
EDA(探索的データ分析)
データを観察し, 性能向上のためにデータの関連性を見つけること
- 「Aが増えるたびにBが減っているな...」, 「〇〇という特徴があると、☆☆という特徴も減っているな...」などの考察が必要
- そこからさらに特徴量エンジニアリングを行っていく
特徴量エンジニアリング
読み込んだデータを機械学習アルゴリズムが扱える形(数値)に変換すること
- 欠損値(Nanデータ) を別の値で埋めたり, データを数値に変換したり, 新しい列を作成
- 既存のデータから, 機械学習アルゴリズムが予測する上で有用な新しい特徴量を作成
- 特徴量エンジニアリングについての参考スライド
- そのコンペが使用しているデータの分野や業界などのドメイン知識も非常に大切
- 性能向上のために思わぬ特徴量を得られることもあるため
- 例えば, 衛星画像のコンペなら天文学を学んだり, 服の画像のコンペならファッション業界を調査してみる, など
欠損値(Nanデータ)の扱い方の理解
- 欠損値としてそのまま使う
- 代表的な値で欠損値を補完する
- 中央値 や平均値, 0などで補完
- 他の特徴量から欠損値を予測して補完する
- 欠損値か否かの情報を用いて新しい特徴量を作る
勾配ブースティングとNN(ニューラルネット)
- 上位陣がよく用いている
- 勾配ブースティングは, LightGBMと呼ばれる手法が人気だが, 他にも色々種類はある
- pytorchやtensorflowなどを用いてNNを実装する場合もある
- 特に現在はNNが人気
ハイパーパラメータの調節
- チューニングツールである 「Oputuna」 を用いる場合があるが, 他にも色々なツールがある.
- しかし, 現実的な時間で終わらないという問題があり, スコアの上がり幅は特徴量エンジニアリングに劣る
- 参加者がNotebookやDiscussionで有用性のある調整済みのハイパーパラメータを公開していることが多いため, コンペの終盤で行うのが良い
- 何度もいうが特徴量エンジニアリングのほうが重要
学習データから検証データを作成
- 検証データを作成し, 手元でスコアを確認することで, public LBのスコアよりも信頼に足る存在になる可能性があるため
- 1日にsubmitできる回数に制限があるため
- 検証方法には, 「ホールドアウト法」 と 「交差検証」 がある
ホールドアウト法
学習データから, trainデータ7割, valデータ3割のように分ける方法.
交差検証
複数回にわたって異なる方法でデータセットを分割し, それぞれホールドアウト検証を実行する方法.
- sklearnに存在する KFold というクラスを用いると便利
- 学習用データセットを無駄にしないというメリット. 与えられたデータセットを漏れなく学習させることができる.
- 各分割でのスコアの平均をスコアと見なすことが多い(CVスコア)
- 各分割で学習に使われなかった分割は Out-of-fold と表現される
- データセットの分割によってはホールドアウト法よりも精度が落ちてしまうので, しっかりとデータセットの課題設定の特徴を意識すること
アンサンブル
複数の機械学習モデルを組み合わせることで性能の高い予測値を獲得する手法. 手法は様々存在する.
- 手法の一種として, 「多数決」 の技法がある
- それぞれのモデルのいい部分, 悪い部分を補完しあい, 全体として良い予測結果を得る精度向上の手法
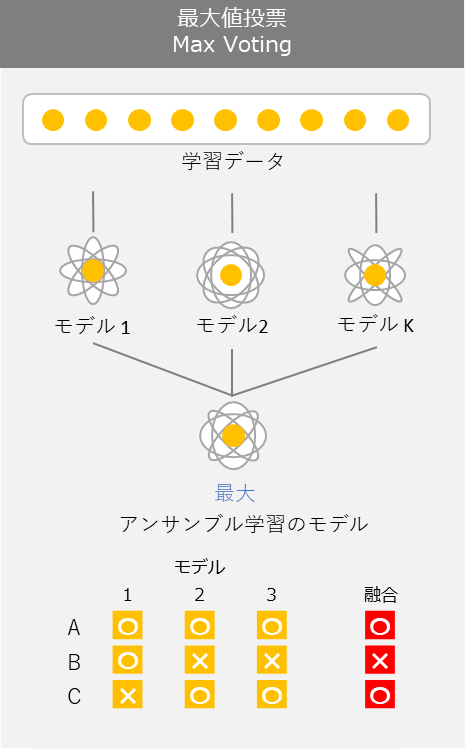
- 基本的にはやればやるほどスコアは伸びる
- 高度なアンサンブルは, 「黒魔術」と呼ばれることもある
テキストデータのコンペに参加!大まかな流れを知る
- まずはEDAをしっかり行い, データ同士の関連性を掴む
- 色々な軸でデータを眺め, 予測性能に寄付しような特徴量を得る
- 必要な列は追加あるいは削除したり, 欠損値はどうするのかなどをしっかり考えながら特徴量エンジニアリングを行う. 超重要!
- 機械学習アルゴリズムの構築, 学習
- 生成した重みは念の為保存しておく(データセットが膨大の��場合は特に). 後々のアンサンブルで活かせる可能性があるため.
- 評価結果からスコア向上を狙う
- ハイパーパラメータの調整
- 時間がかかるのでコンペの終盤. ハイパーパラメータの調整ツールなどを用いると便利.特徴量エンジニアリングほどじゃない.
- 特徴量エンジニアリングの見直し
- ここでかなり変わる
- アンサンブル
- コンペの終盤. 特徴量エンジニアリングほどじゃない.
- 交差検証やホールドアウト法の実行
- 1日にsubmitできる回数は決まっている. むやみやたらにsubmitしない. 評価までして必ず信頼に足るスコアを算出したモデルをsubmitする.
- ハイパーパラメータの調整
画像データの知見
テーブルデータと共通する部分
- 前提として, 機械学習の教師あり学習の枠組みである限り, 学習用データセットの特徴量・目的変数の対応関係を機械学習アルゴリズムで学習して未知のデータセットに対する性能を得るという部分は共通
- 画像データもテーブルデータと同様に, 数値データの集合である
テーブルデータと異なる部分
-
特徴量エンジニアリングの方法
- 伝統的な画像認識
- 「画像のどこに注目し, 何を特徴量として取り出すか」 => 局所特徴量「SIFT」などを用いた上でロジスティック回帰などの機械学習アルゴリズムに投入するやり方
- テーブルデータから特徴量を作っていく過程に似ている
- 近年の画像認識
- 画像から特徴量を抽出する部分をニューラルネットワークに任せる手法が一般的
- 画像のデータセットをそのまま入力として利用し, ニューラルネットワークの高い表現力で有用な特徴量を獲得している
- 画像から特徴量を抽出する部分をニューラルネットワークに任せる手法が一般的
- 伝統的な画像認識
-
特徴量エンジニアリングの方法から, 近年は, 特徴量エンジニアリングへの注力するよりも, ニューラルネットワークの構造設計に注力することが一般的
-
機械学習アルゴリズムに層の深いニューラルネットワーク(Deep Learning)を使うことが多く, 計算量が多いため, GPUを使用することが多い
-
データセットのサイズもテーブルデータとは違って大きいものが多い
テキストデータの知見
テーブルデータと共通する部分
- 機械学習の教師あり学習の枠組みである限り, 学習用データセットの特徴量・目的変数の対応関係を機械学習アルゴリズムで学習して未知のデータセットに対する性能を得るという部分は共通
テーブルデータと異なる部分
- 文章はそのままでは機械学習アルゴリズムで扱えないので, テーブルデータの特徴量のように, 意味のあるベクトルとして見なす必要がある
- 文の特徴を保持したまま, 何かしらの方法でベクトルに変換する必要がある. 以下, その変換方法を述べる.
ベクトルへの変換方法
以下のテキストデータを例に出して説明する.
import pandas as pd
df = pd.DataFrame({'text': ['I like kaggle very much',
'I do not like kaggle',
'I do really love machine learning']})
print(df)
| | text |
| --- | --------------------------------- |
| 0 | I like kaggle very much |
| 1 | I do not like kaggle |
| 2 | I do really love machine learning |
- Bag Of Words
- 文で登場した単語の数を数える方法
- 弱点
- 単語の珍しさを表現できていない.
- 単語同士の近さを考慮できていない.
- 文中の単語の順番に関する情報を捨ててしまっている.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b')
bag = vectorizer.fit_transform(df['text'])
bag.toarray()
array([[0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1],
[1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0],
[1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0]])
print(vectorizer.vocabulary_)
{'i': 1, 'like': 4, 'kaggle': 2, 'very': 10, 'much': 7, 'do': 0, 'not': 8, 'really': 9, 'love': 5, 'machine': 6, 'learning': 3}
- TF-IDE
- 登場する単語の珍しさを考慮した手法
- 単語の登場頻度を数えるだけでなく, ドキュメント内での登場頻度の逆数を掛けている
- Bag Of Wordsは0か1だが, TF-IDEは0~1の連続値をとる. 端午の珍しさに応じて大きな値になる.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
vectorizer = CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b')
transformer = TfidfTransformer()
tf = vectorizer.fit_transform(df['text'])
tfidf = transformer.fit_transform(tf)
print(tfidf.toarray())
[[0. 0.31544415 0.40619178 0. 0.40619178 0.
0. 0.53409337 0. 0. 0.53409337]
[0.43306685 0.33631504 0.43306685 0. 0.43306685 0.
0. 0. 0.56943086 0. 0. ]
[0.34261996 0.26607496 0. 0.45050407 0. 0.45050407
0.45050407 0. 0. 0.45050407 0. ]]
- Word2vec
- 単語同士の意味の近さを捉えたベクトル化の手法
- 絵で理解するWord2vec
- word2vec(Skip-Gram Model)の仕組みを恐らく日本一簡潔にまとめてみたつもり
from gensim.models import word2vec
sentences = [d.split() for d in df['text']]
model = word2vec.Word2Vec(sentences, size=10, min_count=1, window=2, seed=7)
以上で学習が終了. 以下のようにしてベクトルに変換.
model.wv['like']
array([ 0.04312563, 0.03326133, 0.03106231, 0.01843069, 0.0070821 ,
-0.02348904, 0.01093288, -0.04240299, 0.02196812, 0.01367226],
dtype=float32)
以下のようにして, 学習に用いた端午の中から似ている単語を抽出する. 学習に用いるデータセットが最も多ければ, 近しい単語の意味の近さがより学習できる.
model.wv.most_similar('like')
[('kaggle', 0.22822728753089905),
('learning', 0.09379245340824127),
('I', 0.0611097514629364),
('really', 0.02194378525018692),
('love', -0.12185811251401901),
('not', -0.13358381390571594),
('very', -0.2585296034812927),
('do', -0.3249674439430237),
('much', -0.37697386741638184),
('machine', -0.7193681001663208)]
ベクトル化した単語を機械学習アルゴリズムで利用する
1. 文に登場する単語のベクトルの平均をとる
# 文章を単語に分割
df['text'][0].split()
['I', 'like', 'kaggle', 'very', 'much']
import numpy as np
# 各単語をベクトル化
wordvec = np.array([model.wv[word] for word in df['text'][0].split()])
wordvec
array([[-0.00363328, -0.03695147, -0.00932721, 0.02809109, -0.03135956,
-0.00338274, -0.01236197, -0.01804259, 0.02107921, 0.04571741],
[ 0.04312563, 0.03326133, 0.03106231, 0.01843069, 0.0070821 ,
-0.02348904, 0.01093288, -0.04240299, 0.02196812, 0.01367226],
[-0.01280293, 0.00525372, 0.03063563, 0.02622959, 0.04173809,
-0.00310447, -0.02303432, -0.01627791, -0.01022275, -0.01953161],
[-0.02937879, -0.04180092, 0.0457573 , -0.02433218, -0.04171886,
-0.04713685, -0.04785692, 0.04563756, 0.02717528, 0.00408568],
[-0.01501628, -0.01051726, -0.03027121, -0.0269054 , 0.01456141,
0.00104741, -0.00175865, -0.02849161, -0.03361709, -0.03478765]],
dtype=float32)
# ベクトルの平均値の算出
np.mean(wordvec, axis=0)
array([-0.00354113, -0.01015092, 0.01357136, 0.00430276, -0.00193936,
-0.01521314, -0.0148158 , -0.01191551, 0.00527655, 0.00183122],
dtype=float32)
2. 文に登場する単語ベクトルの各要素の最大値をとる
# 最大値の取得
np.max(wordvec, axis=0)
array([0.04312563, 0.03326133, 0.0457573 , 0.02809109, 0.04173809,
0.00104741, 0.01093288, 0.04563756, 0.02717528, 0.04571741],
dtype=float32)
3. 各単語の時系列データとして扱う
- word2vecのベクトルをそのまま時系列の入力として扱う.
- 「文中の単語の順番に関する情報を捨ててしまっている」の部分に対応する手法