Deep Learning with Video
There was an excellent class in the University of Michigan's public lectures, so I am translating and summarizing it here.
Tasks
Video is treated as a tensor of (T x 3 x H x W), where images are arranged as time series data. Sometimes the format is (3 x T x H x W).
The main tasks in the image domain are:
- Classification (whole image)
- Semantic Segmentation (Pixelwise Classification)
- Object Detection (Find bounding box)
- Instance Segmentation (Predict shape)
Video data performs these tasks continuously.
1. Video Classification
- A task of classifying videos into categories. Unlike images, in addition to identifying what an object is, it also classifies human actions from a series of movements.

- A general problem with video is that the data is too large. Uncompressed, assuming 1 byte per entry, one minute of HD video is about 10GB. Therefore, we train on only a portion of the video with reduced FPS and resolution. Model evaluation is done by oversampling portions of the video and taking the average accuracy, which gives accuracy for the entire video.

1-1. Single Frame CNN
A method that classifies each frame as a separate image using independent CNNs. It trains on longer videos and improves accuracy averaged over the number of frames. Since it does not consider relationships between images, it might seem like a poor model at first glance, but it actually performs at a practical level. This is a good baseline when doing video classification.
1-2. Late Fusion
A model that connects the above model to an MLP. Since it integrates per-frame features into one, it can be trained with cross-entropy and can learn relationships between frames, but it is prone to overfitting in the FC layers. As a countermeasure, T, H, W are pooled during feature integration to reduce the data to D dimensions. These methods are also simple and worth trying first.
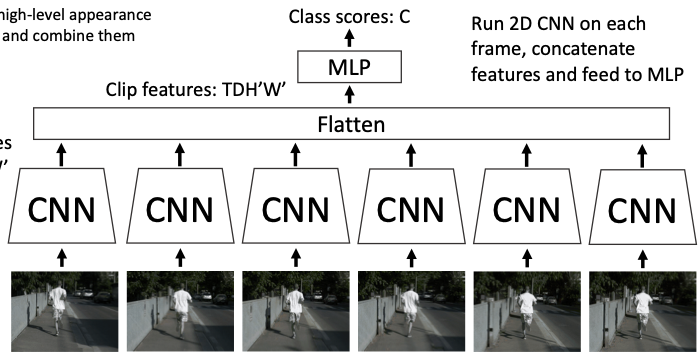
However, since feature integration happens late, small movements in the video cannot be learned. For example, whether a person is walking or standing is determined by small movements of the feet, but these small features tend to be lost before reaching the FC layers.
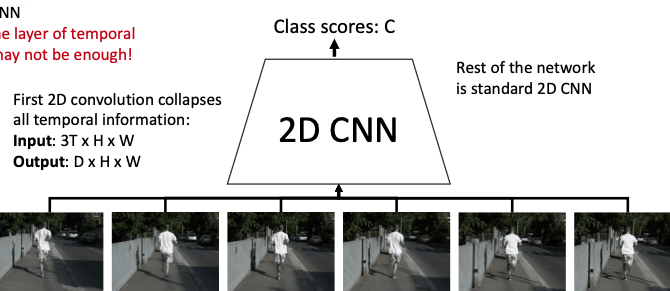
1-3. Early Fusion
Instead of extracting features from each frame first, this model convolves the (3 x T x H x W) video into (3T x H x W) (feature integration) and then trains it as a 3D tensor using a 2D CNN. Fine pixel changes can be learned by the 2D CNN, but since time series data is processed with a single convolution, those temporal features are not well represented.
1-3. Slow Fusion
While Early Fusion only performed convolution in the spatial dimensions and lost temporal information, this method adds the time axis in addition to spatial dimensions for 3D convolution, gradually integrating temporal and spatial features.
1-4. Dataset
- Sport-1M: 1 million YouTube videos labeled with 487 sports categories
Comparison of Methods
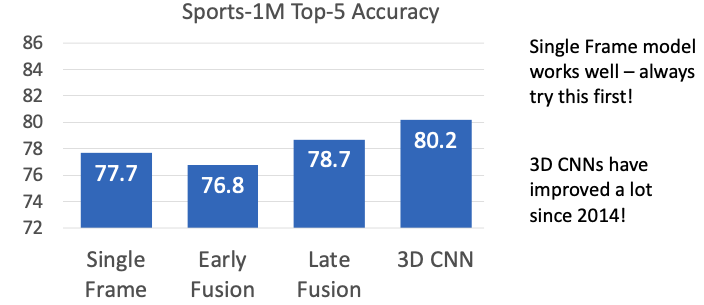
-
Single Frame Simple but performs on par with fusion methods. Try this first.
-
Early
Strong at learning images since it convolves spatially, but has the weakness of not being time shift invariant. This is because the depth of the filter learns temporal changes of each pixel. For example, if a video where a person stands up at the beginning is trained, shifting that video by a few frames would require the filter to shift by that many frames in depth as well.
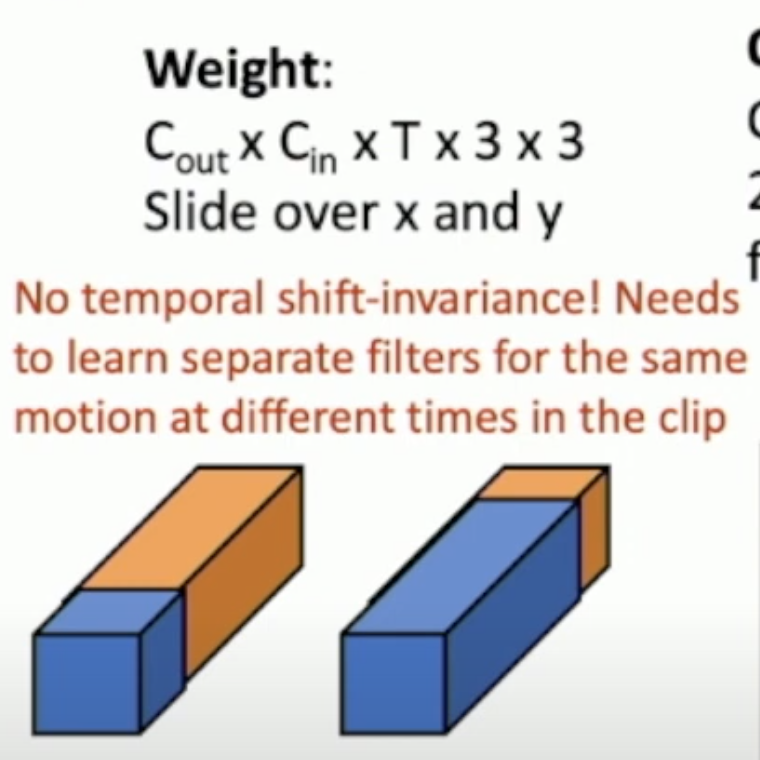
-
Slow
Since filters move across both spatial and temporal axes, it becomes time shift-invariant. Processing input
(Cin x T x H x W)with a(Cin x Cout x 3 x 3 x 3)filter (the three 3s are for T, H, W) outputs the same shape, making the output visualizable. 3D CNNs are actively evolving. C3D, which is VGG with Conv2D replaced by Conv3D, achieves high performance but has very high computational cost. 3D-ResNet went much deeper at once.
2. Action Recognition
A task of predicting what a person is doing from their movements.
2-1. Optical Flow
In addition to image features from each frame, this approach learns the pattern of apparent motion of objects between two consecutive frames (or rather, pixel motion). The former is called the Spatial stream and the latter the Temporal stream, trained in separate networks, with class scores integrated by averaging. Apparently, when deeper models become compatible with this architecture, the results will be impressive.