動画を使った深層学習
ミシガン大学の公開講義にとても良いクラスがあったので翻訳andまとめておきます。
タスク
動画は画像を時系列データとした(T x 3 x H x W)のテンサーで扱う。(3 x T x H x W)の時もある。
画像系のタスクは主に
- Classification (whole image)
- Semantic Segmentation (Pixelwise Classification)
- Object Detection (Find bounding box)
- Instance Segmentation (Predict shape)
があり、動画データはこれを連続的に行う。
1. Video Classification
- 動画をクラス分類するタスク、画像と違い物体が何か当てる以外にも一連の動きから人間の動作を分類したりする。

- 動画の全般的な問題としてデータが��大きすぎる。無圧縮だと1エントリー1 byteとしてHD動画1分で10GBくらい。なのでFPSと解像度を下げた動画の一部分だけを学習させる。モデルの評価は動画の一部をオーバーサンプリングして平均精度を取ることで動画全体への精度がわかる。

1-1. Single Frame CNN
各フレームを別々の画像として独立したCNNで分類する手法。長めの動画を学習させて正答率をフレーム数で平均した精度を向上させていく。画像同士の関係を考慮しないので一見するとダメなモデルっぽいが実は普通に実用レベルで性能が良いらしい。動画分類をする時はこれをベースにやるといい。
1-2. Late Fusion
上のモデルをMLPに接続したモデル。フレーム毎の特徴量を一つに統合するので交差エントロピーで学習できてフレーム同士の関係も学習できるがFC層で過学習を起こしやすい。対策として特徴量の統合時にT, H, WをPoolingしてD次元データに落とし込む。これらの手法もシンプルなのでまず試したいモデ�ル。
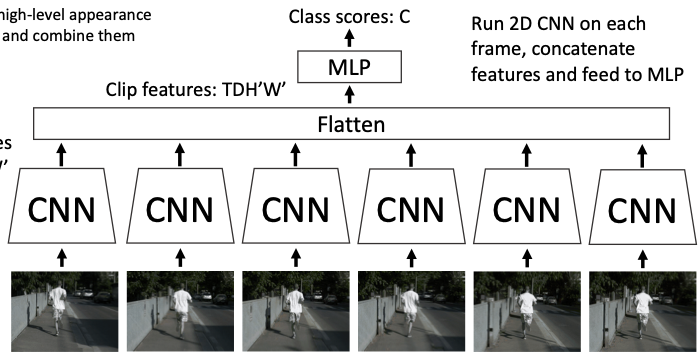
しかし特徴量を統合するのが遅いので、動画の小さい動きを学習できない。例えば、人が歩いてるか立っているかは足の小さな動きで判断するが、FC層に来る前にこれらの小さい特徴量は失われやすい。
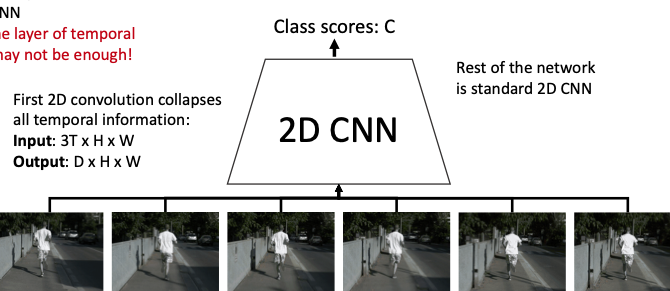
1-3. Early Fusion
先に各フレームの特徴量を抽出するのではなく、(3 x T x H x W)の動画を(3T x H x W)になるように畳み込み(特徴量の統合)してから、3次元テンサーとしてから2DCNNで学習するモデル。ピクセルの細かい変化も2DCNNが学習できるが、時系列データを一回の畳み込みで処理するのでそこら辺の特徴量は上手く表現されない。
1-3. Slow Fusion
Early Fusionでは縦横での畳み込みしか行わなず時系列の情報は失われていたが、縦横に加え時間軸も加えた3次元で畳み込みを行い、時間と空間の特徴を徐々に統合していく手法。
1-4.データセット
- Sport-1M: YouTubeの100万枚の動画に487のスポーツのカテゴリーが付与されている
各手法の比較
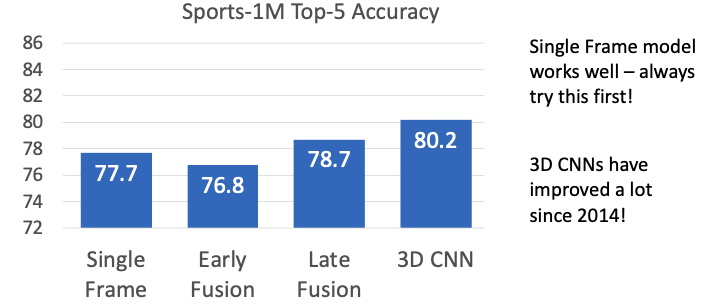
-
Single Frame シンプルだが統合系に劣らない性能、とりあえずこれを最初に試そう。
-
Early
縦横で畳み込む為画像としての学習は強いが、Time shift invavriantじゃないという弱点もある。 これはフィルターの奥行きがそのピクセルの時間による変化を学習しちゃうのが原因で、例えば最初の方で人が立ち上がる動画を学習したとして、その動画を数フレームずらした場合フィルターも奥にそのフレーム分ズレる必要がある。
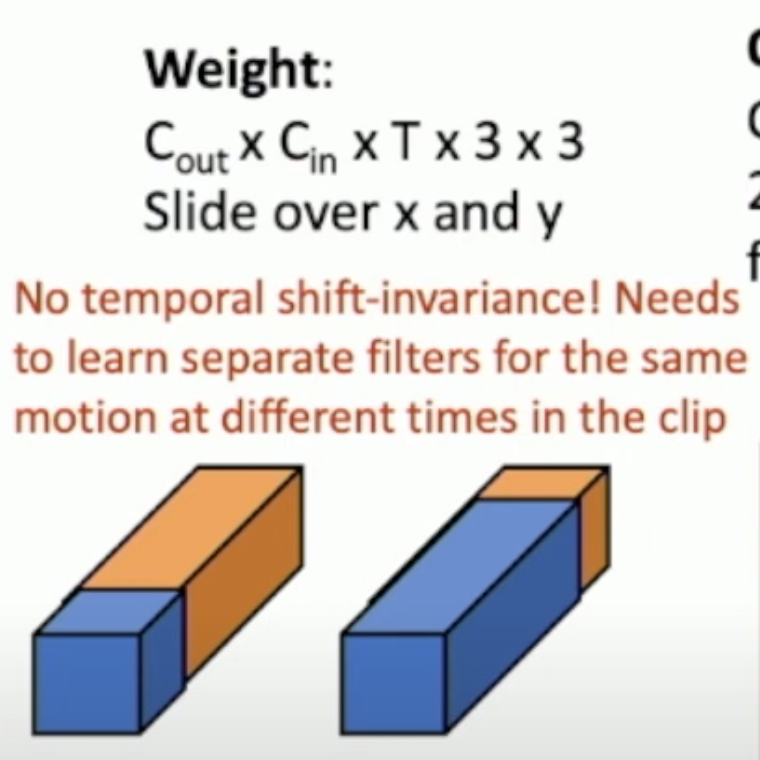
-
Slow
縦横と時間軸でフィルターを動かすのでtime shift-invariantになる。入力
(Cin x T x H x W)を(Cin x Cout x 3 x 3 x 3)フィルターで処理すれば(三つの3はTHW用)同じ形で出力するので出力も見える化できる。3DCNNは絶賛進化中な模様。Conv2DをConv3DにしたVGGC3Dが高性能だが計算量は非常に多い。3D-ResNetで一気にディープに。
2. 行動認識
人の動きから何をしているか予測するタスク。
2-1. Optical Flow
各フレームの画像特徴量に追加で連続した2フレーム間の物体の動きの見え方のパターンを学習する(ピクセルの動きと言うべきか)。前者をSpatial stream, 後者をTemporal streamという別のネットワークで学習しクラススコアを平均で統合する。 層が深いモデルがこのアーキテクチャーに対応したらやばいらしい。