【もうやりたくない】RNNとLSTMの理解とNumPyによる実装
ニューラルネットワークを用いた系列データを学習する方法について書きます。系列データの学習には、単語予測や天気予測など様々な応用先があります。
この流れで解説していきたいと思います。
- ニューラルネットワークでは、カテゴリー変数の表現の仕方
- RNNの実装の仕方
- LSTMの実装の仕方
- PyTorchを使ったLSTMの実装の仕方
時系列データの表現の仕方
時系列データをニューラルネットワークに入力するには、何かしらの方法で時系列データをニューラルネットワークに入力できる形に表現する必要があります。ここでは、one-hot encodingを使用していきたいと思います。
単語に対するone-hot encoding
単語をone-hot vectorに変換します。しかし、単語の量が膨大になるとone-hot vectorの大きさも膨大になるので、工夫を行います。
使用頻度の高いk個の単語を残しそれ以外の単語はUNKとして、one-hot vectorに変換します。
データセットの生成
a b a EOS,
a a b b a a EOS,
a a a a a b b b b b a a a a a EOS
のようなデータセットを生成することを考えます。
EOSは、end of a sequenceの略です。
import numpy as np
np.random.seed(42)#乱数を固定する
def generate_dataset(num_sequences=2**8):
"""
データセットを生成する関数
num_sequences 周期
return 系列データのリスト
"""
samples = []
for _ in range(num_sequences):
num_tokens = np.random.randint(1, 6)#1から6までの数を1つ生成
sample = ['a'] * num_tokens + ['b'] * num_tokens + ['a'] * num_tokens + ['EOS']
samples.append(sample)
return samples
sequences = generate_dataset()
系列データの単語とその出現頻度を調べる
one-hot encodingをするために、系列データの単語とその出現頻度を格納している辞書を作ります。
defaultdictを使うことで、辞書のvalueの値を任意に初期化できるみたいです。
from collections import defaultdict
def sequences_to_dicts(sequences):
"""
単語とその出現頻度を格納する辞書を作る
"""
flatten = lambda l: [item for sublist in l for item in sublist]#listを全部つなげる
all_words = flatten(sequences)
word_count = defaultdict(int)#辞書の初期化
for word in flatten(sequences):
#頻度を数える
word_count[word] += 1
word_count = sorted(list(word_count.items()), key=lambda l: -l[1])#word_countのkeyとvalueをvalueに基づいて降順にソート
unique_words = [item[0] for item in word_count]#単語をとる
unique_words.append('UNK')#UNKを追加
num_sequences, vocab_size = len(sequences), len(unique_words)
word_to_idx = defaultdict(lambda: vocab_size-1)#初期値の設定
idx_to_word = defaultdict(lambda: 'UNK')
for idx, word in enumerate(unique_words):
#enumerateでindexと要素を取得
#辞書に入れる
word_to_idx[word] = idx
idx_to_word[idx] = word
return word_to_idx, idx_to_word, num_sequences, vocab_size
word_to_idx, idx_to_word, num_sequences, vocab_size = sequences_to_dicts(sequences)
データセットの分割
系列データをtraining, validation, testに分割します。 それぞれ、80%, 10%, 10%です。 系列データsequencesの分割には、スライスを使っています。
スライスを使うと、l[start:goal]でl[start]からl[goal-1]の値を抽出できます。startとgoalは半開区間になっており、l[goal]は含まれません。
startとgoalは省略することができます。
l[:goal]はl[0]からl[goal-1]まで、
l[start:]はl[start]からl[l.size()-1](最後)まで抽出できます。
l[:]は全部抽出します。
l[-n:]は最後から数えてn個の要素を抽出します。
l[:-n]はl[0]から抽出しますが、最後のn個は抽出しません。
PyTorchを用いてデータセットを定義します。
from torch.utils import data
class Dataset(data.Dataset):
def __init__(self, inputs, targets):
self.intputs = inputs
self.targets = targets
def __len__(self):
return len(self.targets)
def __getitem__(self, index):
X = self.inputs[index]
y = self.targets[index]
return X, y
def create_datasets(sequences, dataset_class, p_train=0.8, p_val=0.1, p_test=0.1):
#分割するサイズを定義
num_train = int(len(sequences)*p_train)
num_val = int(len(sequences)*p_val)
num_test = int(len(sequences)*p_test)
#系列データを分割
#スライスを利用
sequences_train = sequences[:num_train]
sequences_val = sequences[num_train:num_train+num_val]
sequences_test = sequences[-num_test:]
def get_inputs_targets_from_sequences(sequences):
inputs, targets = [], []
#長さLのsequenceからEOSを除いたL-1
# targetsはinputsのground truthのため右に1つずらす
for sequence in sequences:
inputs.append(sequence[:-1])
targets.append(sequence[1:])
return inputs, targets
#inputとtargetを作る
inputs_train, targets_train = get_inputs_targets_from_sequences(sequences_train)
inputs_val, targets_val = get_inputs_targets_from_sequences(sequences_val)
inputs_test, targets_test = get_inputs_targets_from_sequences(sequences_test)
#先ほど定義したclassを用いてdatasetを作る
training_set = dataset_class(inputs_train, targets_train)
validation_set = dataset_class(inputs_val, targets_val)
test_set = dataset_class(inputs_test, targets_test)
return training_set, validation_set, test_set
training_set, validation_set, test_set = create_datasets(sequences, Dataset)
one-hot vector化
系列データに現れる単語を頻度に基づいてone-hot vectorに変換します。
def one_hot_encode(idx, vocab_size):
"""
one-hot vector化する。
"""
one_hot = np.zeros(vocab_size)#vocab_size = 4なら[0, 0, 0, 0]
one_hot[idx] = 1.0#idx = 1なら[0, 1, 0, 0]
return one_hot
def one_hot_encode_sequence(sequence, vocab_size):
"""
return 3-D numpy array (num_words, vocab_size, 1)
"""
encoding = np.array([one_hot_encode(word_to_idx[word], vocab_size) for word in sequence])
#reshape
encoding = encoding.reshape(encoding.shape[0], encoding.shape[1], 1)
return encoding
RNNの導入
Recurrent neural network (RNN)は、系列データの分析が得意です。RNNは、前の状態で使った計算結果を現在�の状態に利用することができます。ネットワークの概要図は以下の通りです。
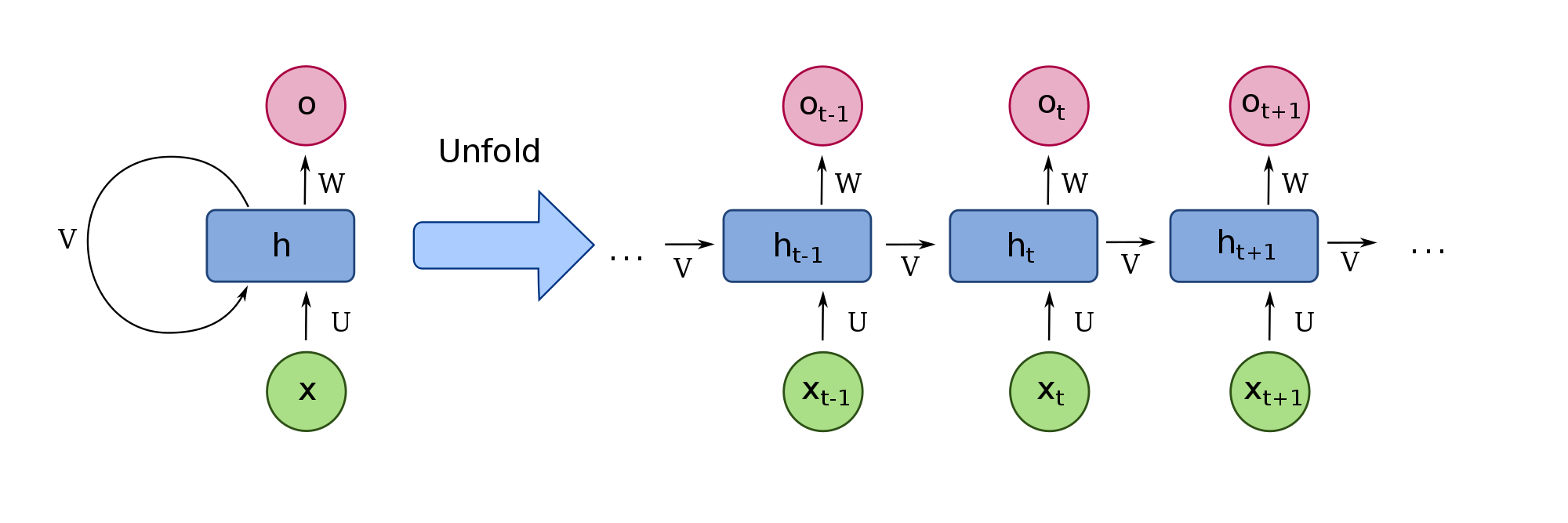
- xは入力である系列データ
- Uは入力に対する重み行列
- Vはメモリーに対する重み行列
- Wは出力を計算するための隠れ状態に対する重み行列
- hは時間ごとの隠れ状態(メモリー)
- oは出力
RNNの実装
NumPyを使って、RNNの実装をforward pass, backward pass, optimization, training loopの順でやります。
RNNの初期化
ネットワークを初期化する関数を定義します。
hidden_size = 50#隠れ層(メモリー)の次元
vocab_size = len(word_to_idx)
def init_orthogonal(param):
"""
パラメータを直交化して初期化
"""
if param.ndim < 2:
raise ValueError("Only parameters with 2 or more dimensions are supported.")
rows, cols = param.shape
new_param = np.random.randn(rows, cols)
if rows < cols:
new_param = new_param.T
q, r = np.linalg.qr(new_param)
d = np.diag(r, 0)
ph = np.sign(d)
q *= ph
if rows < cols:
q = q.T
new_param = q
return new_param
def init_rnn(hidden_size, vocab_size):
"""
RNNを初期化
"""
U = np.zeros((hidden_size, vocab_size))
V = np.zeros((hidden_size, hidden_size))
W = np.zeros((vocab_size, hidden_size))
b_hidden = np.zeros((hidden_size, 1))
b_out = np.zeros((vocab_size, 1))
U = init_orthogonal(U)
V = init_orthogonal(V)
W = init_orthogonal(W)
return U, V, W, b_hidden, b_out
活性化関数の実装
sigmoid,tanh, softmaxの実装をしました。 オーバーフロー対策に入力xに微少量を足しています。 また、backward pass用に微分も計算しています。
def sigmoid(x, derivative=False):
x_safe = x + 1e-12#微少量を足す
f = 1/(1 + np.exp(-x_safe))
if derivative:
return f * (1 -f)#微分を返す
else:
return f
def tanh(x, derivative=False):
x_safe = x + 1e-12
f = (np.exp(x_safe) - np.exp(-x_safe))/(np.exp(x_safe)+np.exp(-x_safe))
if derivative:
return 1-f**2
else:
return f
def softmax(x, derivative=False):
x_safe = x + 1e-12
f = np.exp(x_safe)/np.sum(np.exp(x_safe))
if derivative:
pass
else:
return f
forward passの実装
- h = tanh(Ux + Vh + b_hidden)
- o = softmax(Wh + b_out) RNNのforward passは上式で表されるので、実装は以下の通りです。
def forward_pass(inputs, hidden_state, params):
U, V, W, b_hidden, b_out = params
outputs, hidden_states = [], []
for t in range(len(inputs)):
hidden_state = tanh(np.dot(U, inputs[t]) + np.dot(V, hidden_state) + b_hidden)
out = softmax(np.dot(W, hidden_state) + b_out)
outputs.append(out)
hidden_states.append(hidden_state.copy())
return outputs, hidden_states
backward passの実装
forward passで損失の勾配を計算するのは時間がかかるので、逆誤差伝播法(backpropagation)を用いて勾配を計算するbackward passを実装します。
勾配爆発対策用の勾配をクリップする関数を作ります。 勾配の大きさが上限値を超えたら、上限値で正規化します。
def clip_gradient_norm(grads, max_norm=0.25):
"""
勾配爆発対策で
勾配を
g = (max_nrom/|g|)*gに変換する
"""
max_norm = float(max_norm)
total_norm = 0
for grad in grads:
grad_norm = np.sum(np.power(grad, 2))
total_norm += grad_norm
total_norm = np.sqrt(total_norm)
clip_coef = max_norm / (total_norm + 1e-6)
if clip_coef < 1:
for grad in grads:
grad *= clip_coef
return grads
backward_passを計算する関数を作ります。損失を求めて、逆誤差伝播法でそれぞれのパラメータで微分した損失の勾配を求めます。
def backward_pass(inputs, outputs, hidden_states, targets, params):
U, V, W, b_hidden, b_out = params
d_U, d_V, d_W = np.zeros_like(U), np.zeros_like(V), np.zeros_like(W)
d_b_hidden, d_b_out = np.zeros_like(b_hidden), np.zeros_like(b_out)
d_h_next = np.zeros_like(hidden_states[0])
loss = 0
for t in reversed(range(len(outputs))):
#cross entropy lossを計算
loss += -np.mean(np.log(outputs[t]+1e-12)*targets[t])
#backpropagate into output
d_o = outputs[t].copy()
d_o[np.argmax(targets[t])] -= -1
#backpropagate into W
d_W += np.dot(d_o, hidden_states[t].T)
d_b_out += d_o
#backpropagate into h
d_h = np.dot(W.T, d_o) + d_h_next
#backpropagate through non-linearity
d_f = tanh(hidden_states[t], derivative=True) * d_h
d_b_hidden += d_f
#backpropagate into U
d_U += np.dot(d_f, inputs[t].T)
#backpropagate into V
d_V += np.dot(d_f, hidden_states[t-1].T)
d_h_next = np.dot(V.T, d_f)
grads = d_U, d_V, d_W, d_b_hidden, d_b_out
grads = clip_gradient_norm(grads)
return loss, grads
optimization
勾配降下法を用いて、RNNのパラメータを更新します。今回は確率的勾配降下法(SGD)を使用します。
def update_paramaters(params, grads, lr=1e-3):
for param, gras in zip(params, grads):
#zipで複数のリストの要素を取得
param -= lr * grad
return params
学習
実装したRNNの学習を行います。LossのグラフはTensorBoardを使用して描画しました。
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(log_dir="./logs")#SummaryWriter のインスタンスを生成 保存するディレクトリも指定
num_epochs = 1000
#パラメータの初期化
params = init_rnn(hidden_size=hidden_size, vocab_size=vocab_size)
hidden_state = np.zeros((hidden_size, 1))
for i in range(num_epochs):
epoch_training_loss = 0
epoch_validation_loss = 0
#validationのループ sentenceごとにループを回す
for inputs, targets in validation_set:
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_one_hot = one_hot_encode_sequence(targets, vocab_size)
#初期化
hidde_state = np.zeros_like(hidden_state)
#forward pass
outputs, hidden_states = forward_pass(inputs_one_hot, hidden_state, params)
#backward pass 今はvalidationなのでLossのみを計算
loss, _ = backward_pass(inputs_one_hot, outputs, hidden_states, targets_one_hot, params)
epoch_validation_loss += loss
#trainingのループ sentenceごとにループを回す
for inputs, targets in training_set:
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_one_hot = one_hot_encode_sequence(targets, vocab_size)
#初期化
hidde_state = np.zeros_like(hidden_state)
#forward pass
outputs, hidden_states = forward_pass(inputs_one_hot, hidden_state, params)
#backward pass trainingなので勾配も計算
loss, grads = backward_pass(inputs_one_hot, outputs, hidden_states, targets_one_hot, params)
if np.isnan(loss):
raise ValueError('Gradients have vanished')
#networkのパラメータを更新
params = update_paramaters(params, grads)
epoch_training_loss += loss
writer.add_scalars("Loss", {"val":epoch_validation_loss/len(validation_set), "train":epoch_training_loss/len(training_set)}, i)
writer.close()
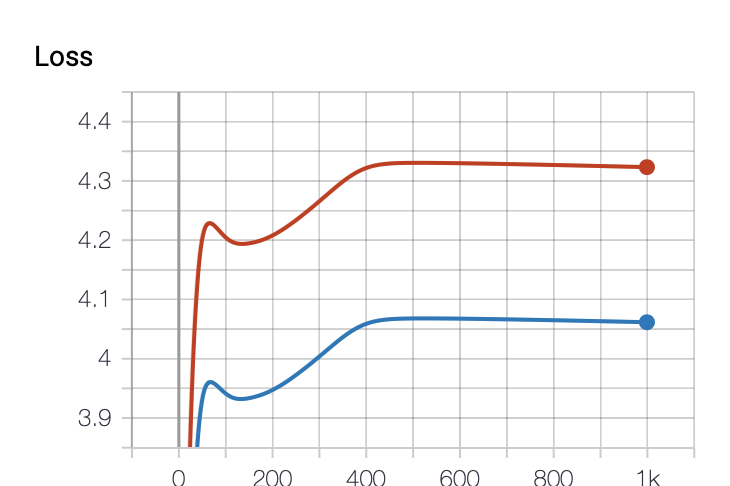
Lossのグラフです。綺麗にプロットできています。赤がtrain, 青がvalを表しています。 あまり上手く学習できていないことがわかります。隠れ層の次元が少ないことやループが少ないことやパラメータの初期値が合ってないことが原因でしょうか?
テスト
学習したRNNのテストをします。適当に文章を生成し、それに対して次のwordを予測します。
Pythonでは、list[-1]で一番後ろの値を取得することができるみたいです。
def freestyle(params, sentence='', num_generate=10):
sentence = sentence.split(' ')#空白で区切る
sentence_one_hot = one_hot_encode_sequence(sentence, vocab_size)
hidden_state = np.zeros((hidden_size, 1))
outputs, hidden_states = forward_pass(sentence_one_hot, hidde_state, params)
output_sentence = sentence
word = idx_to_word[np.argmax(outputs[-1])]
output_sentence.append(word)
for i in range(num_generate):
output = outputs[-1]#一番後ろの値を取得
hidden_state = hidden_states[-1]
output = output.reshape(1, output.shape[0], output.shape[1])
outputs, hidden_states = forward_pass(output, hidde_state, params)
word = idx_to_word[np.argmax(outputs)]
output_sentence.append(word)
if word == "EOS":
break
return output_sentence
test_examples = ['a a b', 'a a a a b', 'a a a a a a b', 'a', 'r n n']
for i, test_example in enumerate(test_examples):
print(f'Example {i}:', test_example)
print('Predicted sequence:', freestyle(params, sentence=test_example), end='\n\n')
上手く学習していないので、テストも上手くいってないことが結果からわかります。 全てUnknownと予測しています。
Example 0: a a b
Predicted sequence: ['a', 'a', 'b', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK']
Example 1: a a a a b
Predicted sequence: ['a', 'a', 'a', 'a', 'b', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK']
Example 2: a a a a a a b
Predicted sequence: ['a', 'a', 'a', 'a', 'a', 'a', 'b', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK']
Example 3: a
Predicted sequence: ['a', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK']
Example 4: r n n
Predicted sequence: ['r', 'n', 'n', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK', 'UNK']
LSTMの導入
RNNは、ギャップが大きくなるにつれて情報を関連づけて学習するのが難しくなります。 このような長期依存性を学習できるようにしたのが、Long Short Term Memory(LSTM)です。LSTMは、RNNの派生で同じように繰り返しモジュールになっています。
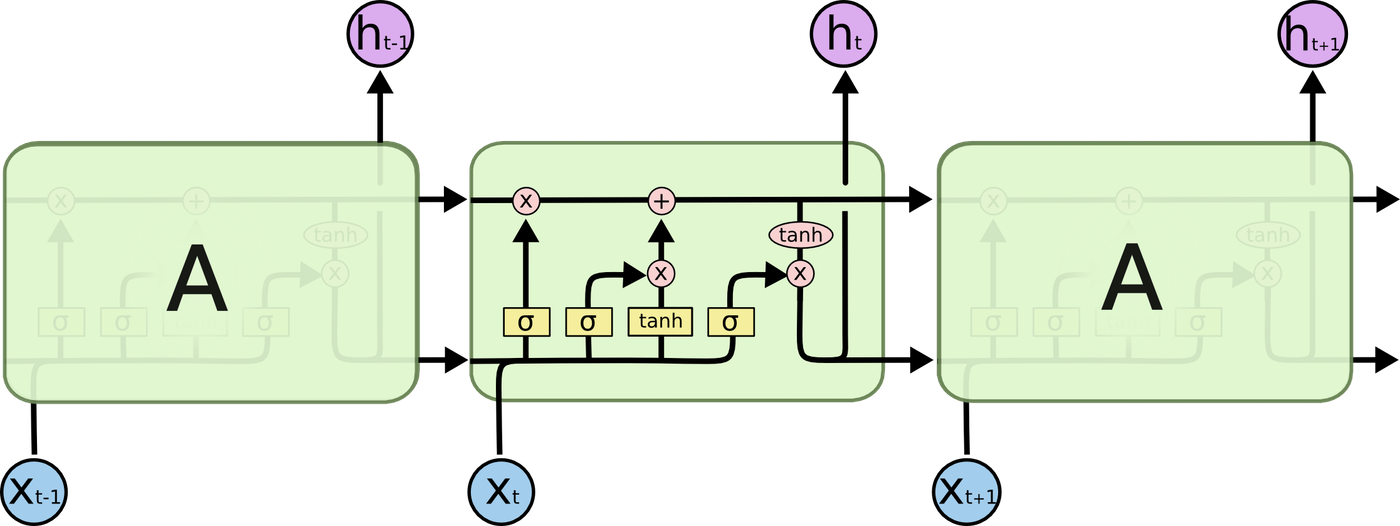
LSTMの仕組み
LSTMは、忘却ゲート層、入力ゲート層、出力ゲート層の3つで構成されています。 LSTMはセルと呼ばれるメモリーが情報を保持しています。Cがセル、xが入力、hが出力、Wが重み、bがバイアスです。
まず、忘却ゲート層で、セル状態から捨てる情報を判定します。現在の入力と、1ステップ前の出力をシグモイド関数にいれます。0から1の間の数値が出力されます。0が完全に捨てるを表し、1が完全に維持を表します。
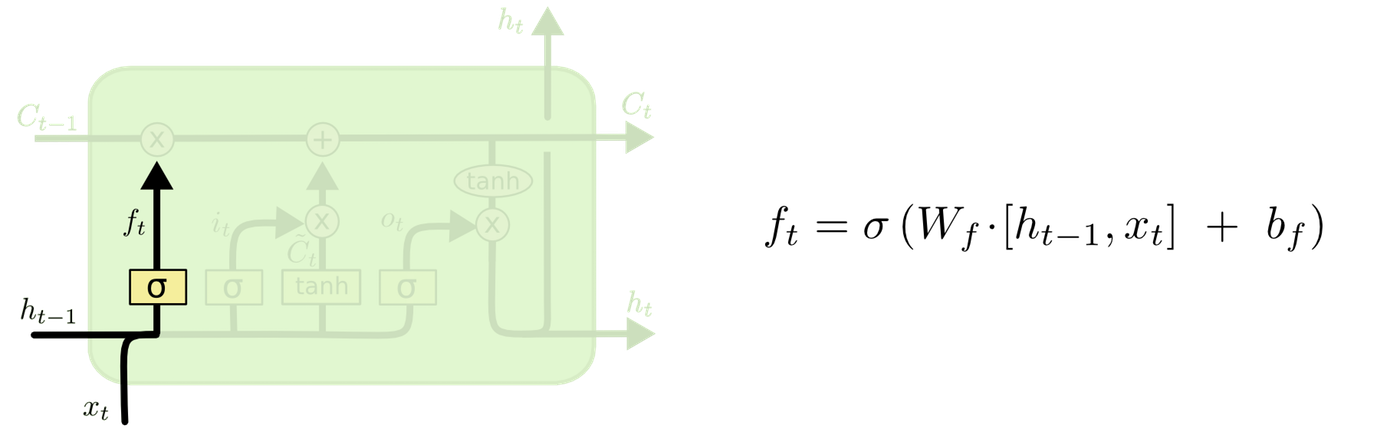
次に、入力ゲート層で、入力に対してどの値を更新するかを判定します。tanh層でセル状態に加えられる新たな候補値のベクトルを作成します。
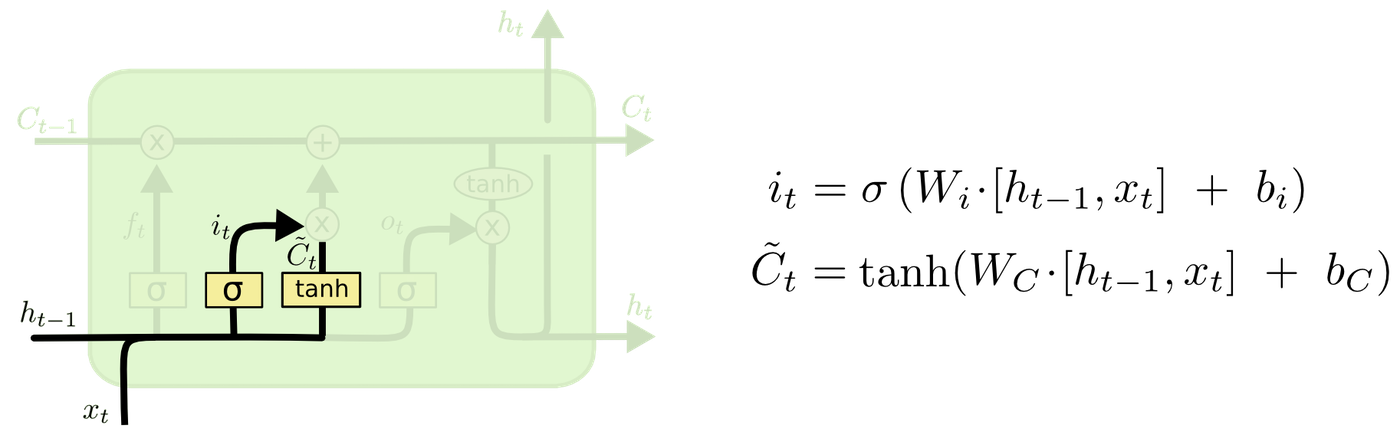
セルを更新します。1ステップ前の忘却済みのセルと更新する値を足し合わせます。
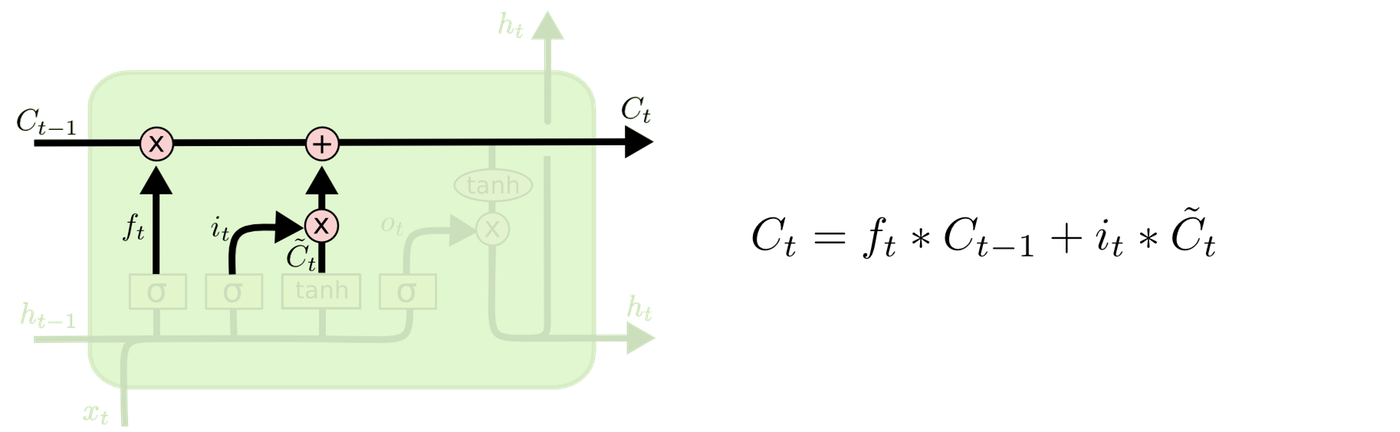
最後に、出力ゲート層で、セル状態に基づいて出力するものを判定します。
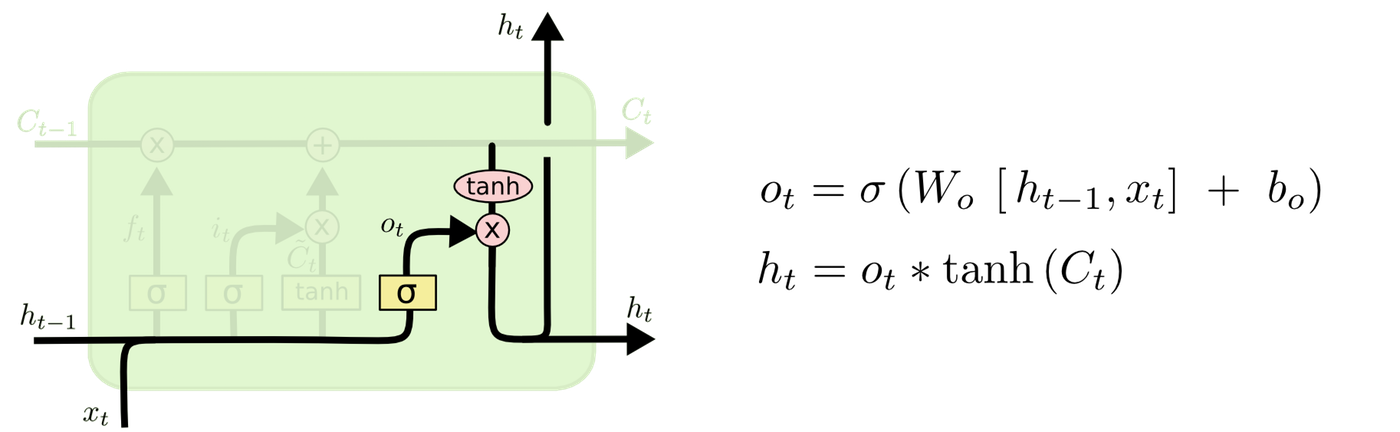
LSTMの実装
NumPyを使って、LSTMの実装をforward pass, backward pass, optimization, training loopの順でやります。
LSTMの初期化
ネットワークを初期化する関数を定義します。
z_size = hidden_size + vocab_size
def init_lstm(hidden_size, vocab_size, z_size):
"""
LSTMの初期化
"""
W_f = np.random.randn(hidden_size, z_size)
b_f = np.zeros((hidden_size, 1))
W_i = np.random.randn(hidden_size, z_size)
b_i = np.zeros((hidden_size, 1))
W_g = np.random.randn(hidden_size, z_size)
b_g = np.zeros((hidden_size, 1))
W_o = np.random.randn(hidden_size, z_size)
b_o = np.zeros((hidden_size, 1))
W_v = np.random.randn(vocab_size, hidden_size)
b_v = np.zeros((vocab_size, 1))
W_f = init_orthogonal(W_f)
W_i = init_orthogonal(W_i)
W_g = init_orthogonal(W_g)
W_o = init_orthogonal(W_o)
W_v = init_orthogonal(W_v)
return W_f, W_i, W_g, W_o, W_v, b_f, b_i, b_g, b_o, b_v
forward passの実装
LSTMの仕組みにあるデータの流れ通りに実装します。
def forward(inputs, h_prev, C_prev, p):
"""
inputs:現在の入力
h_prev:1ステップ前の出力
C_prev:1ステップ前のセル
p:LSTMのパラメータ
return 各モジュールの状態と出力
"""
assert h_prev.shape == (hidden_size, 1)
assert C_prev.shape == (hidden_size, 1)
W_f, W_i, W_g, W_o, W_v, b_f, b_i, b_g, b_o, b_v = p
x_s, z_s, f_s, i_s = [], [], [], []
g_s, C_s, o_s, h_s = [], [], [], []
v_s, output_s = [], []
h_s.append(h_prev)
C_s.append(C_prev)
for x in inputs:
#入力と1ステップ前の出力を結合
z = np.row_stack((h_prev, x))
z_s.append(z)
#忘却ゲート
f = sigmoid(np.dot(W_f, z) + b_f)
f_s.append(f)
#入力ゲート
i = sigmoid(np.dot(W_i, z) + b_i)
i_s.append(i)
#現在の入力��に対してセルに加える候補
g = tanh(np.dot(W_g, z) + b_g)
g_s.append(g)
#セルの更新
C_prev = f * C_prev + i * g
C_s.append(C_prev)
#出力ゲート
o = sigmoid(np.dot(W_o, z) + b_o)
o_s.append(o)
#出力する
h_prev = o * tanh(C_prev)
h_s.append(h_prev)
v = np.dot(W_v, h_prev) + b_v
v_s.append(v)
output = softmax(v)
output_s.append(output)
return z_s, f_s, i_s, g_s, C_s, o_s, h_s, v_s, output_s
backward passの実装
損失を求めて、逆誤差伝播法でそれぞれのパラメータで微分した損失の勾配を求めます。
def backward(z, f, i, g, C, o, h, v, outputs, targets, p = params):
W_f, W_i, W_g, W_o, W_v, b_f, b_i, b_g, b_o, b_v = p
#勾配を初期化
W_f_d = np.zeros_like(W_f)
b_f_d = np.zeros_like(b_f)
W_i_d = np.zeros_like(W_i)
b_i_d = np.zeros_like(b_i)
W_g_d = np.zeros_like(W_g)
b_g_d = np.zeros_like(b_g)
W_o_d = np.zeros_like(W_o)
b_o_d = np.zeros_like(b_o)
W_v_d = np.zeros_like(W_v)
b_v_d = np.zeros_like(b_v)
#次のセルと隠れ状態を初期化
dh_next = np.zeros_like(h[0])
dC_next = np.zeros_like(C[0])
loss = 0
for t in reversed(range(len(outputs))):
#クロスエントロピーロスを計算
loss += -np.mean(np.log(outputs[t]) * targets[t])
#前のセルを更新
C_prev = C[t-1]
dv = np.copy(outputs[t])
dv[np.argmax(targets[t])] -= 1
W_v_d += np.dot(dv, h[t].T)
b_v_d += dv
dh = np.dot(W_v.T, dv)
dh += dh_next
do = dh * tanh(C[t])
do = sigmoid(o[t], derivative=True)*do
W_o_d += np.dot(do, z[t].T)
b_o_d += do
dC = np.copy(dC_next)
dC += dh * o[t] * tanh(tanh(C[t]), derivative=True)
dg = dC * i[t]
dg = tanh(g[t], derivative=True) * dg
W_g_d += np.dot(dg, z[t].T)
b_g_d += dg
di = dC * g[t]
di = sigmoid(i[t], True) * di
W_i_d += np.dot(di, z[t].T)
b_i_d += di
df = dC * C_prev
df = sigmoid(f[t]) * df
W_f_d += np.dot(df, z[t].T)
b_f_d += df
dz = (np.dot(W_f.T, df) + np.dot(W_i.T, di) + np.dot(W_g.T, dg) + np.dot(W_o.T, do))
dh_prev = dz[:hidden_size, :]
dC_prev = f[t] * dC
grads = W_f_d, W_i_d, W_g_d, W_o_d, W_v_d, b_f_d, b_i_d, b_g_d, b_o_d, b_v_d
grads = clip_gradient_norm(grads)
return loss, grads
学習
実装したLSTMの学習を行います。LossのグラフはTensorBoardを使用して描画しました。
writer = SummaryWriter(log_dir="./logs/lstm")#SummaryWriter のインスタンスを生成 保存するディレクトリも指定
num_epochs = 200#エポック数
#LSTMの初期化
z_size = hidden_size + vocab_size
params = init_lstm(hidden_size, vocab_size, z_size)
#隠れ層の初期化
hidden_state = np.zeros((hidden_size, 1))
for i in range(num_epochs):
epoch_training_loss = 0
epoch_validation_loss = 0
#validationのループ sentenceごとにループを回す
for inputs, targets in validation_set:
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_one_hot = one_hot_encode_sequence(targets, vocab_size)
#初期化
h = np.zeros((hidden_size, 1))
c = np.zeros((hidden_size, 1))
#forward pass
z_s, f_s, i_s, g_s, C_s, o_s, h_s, v_s, outputs = forward(inputs_one_hot, h, c, params)
#backward pass 今はvalidationなのでLossのみを計算
loss, _ = backward(z_s, f_s, i_s, g_s, C_s, o_s, h_s, v_s, outputs, targets_one_hot, params)
epoch_validation_loss += loss
#trainのループ sentenceごとにループを回す
for inputs, targets in training_set:
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_one_hot = one_hot_encode_sequence(targets, vocab_size)
#初期化
h = np.zeros((hidden_size, 1))
c = np.zeros((hidden_size, 1))
#forward pass
z_s, f_s, i_s, g_s, C_s, o_s, h_s, v_s, outputs = forward(inputs_one_hot, h, c, params)
#backward pass 今はtrainingなのでLossと勾配を計算
loss, grads = backward(z_s, f_s, i_s, g_s, C_s, o_s, h_s, v_s, outputs, targets_one_hot, params)
#LSTMの更新
params = update_paramaters(params, grads, lr=1e-1)
epoch_training_loss += loss
writer.add_scalars("LSTM Loss", {"val":epoch_validation_loss/len(validation_set), "train":epoch_training_loss/len(training_set)}, i)
writer.close()
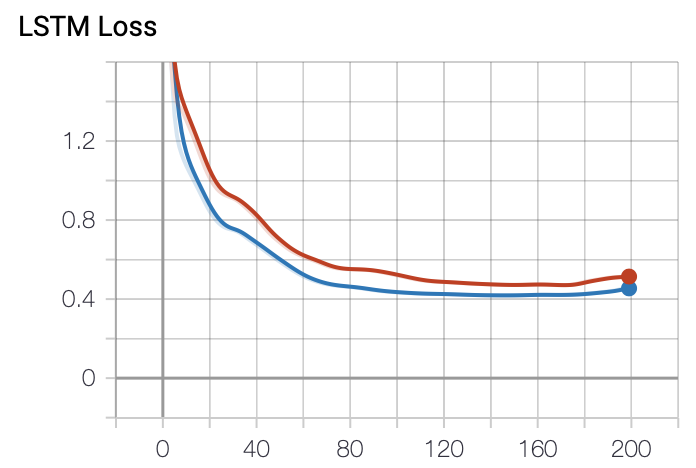
Lossのグラフです。綺麗にプロットできています。赤がtrain, 青がvalを表しています。 RNNと比較すると、学習が進むにつれてLossがしっかりと下がっているので安定しています。
PyTorchを用いたLSTMの実装
フレームワークを使ってLSTMの実装を行います。
LSTMの定義
まず、LSTMのネットワークを定義します。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyLSTM(nn.Module):
def __init__(self):
super(MyLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=vocab_size, hidden_size=50, num_layers=1, bidirectional=False)
self.l_out = nn.Linear(in_features=50, out_features=vocab_size, bias=False)
def forward(self, x):
x, (h, c) = self.lstm(x)
x = x.view(-1, self.lstm.hidden_size)
x = self.l_out(x)
return x
学習
学習するためのループを書きます。 ロス関数はクロスエントロピー誤差を、optimizerはSGDを用いました。 numpyを用いたときと同様です。
PyTorchでは、クロスエントロピー誤差を用いるとき、targetはone-hot vectorにするのではなく1である箇所(正解の箇所)のインデックスを渡すだけでよいです。
LossのグラフはTensorBoardを使用して描画しました。
num_epochs = 200#エポック数
net = MyLSTM()#LSTMのインスタンス生成
net = net.double()#型をfloatからdoubleに変換
criterion = nn.CrossEntropyLoss()#クロスエントロピー誤差を使用
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1)#optimizerを設定
writer = SummaryWriter(log_dir="./logs/lstm_pytorch")#SummaryWriter のインスタンスを生成 保存するディレクトリも指定
for i in range(num_epochs):
epoch_training_loss = 0
epoch_validation_loss = 0
net.eval()#テストモード
#validationのループ sentenceごとにループを回す
for inputs, targets in validation_set:
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_idx = [word_to_idx[word] for word in targets]
inputs_one_hot = torch.from_numpy(inputs_one_hot)
inputs_one_hot = inputs_one_hot.permute(0, 2, 1)
targets_idx = torch.LongTensor(targets_idx)
#forward pass 今はvalidationなのでLossのみを計算
outputs = net(inputs_one_hot)
loss = criterion(outputs, targets_idx)
epoch_validation_loss += loss.item()
net.train()#訓練モード
#trainのループ sentenceごとにループを回す
for inputs, targets in training_set:
optimizer.zero_grad()#勾配の初期化
#one-hot vector化
inputs_one_hot = one_hot_encode_sequence(inputs, vocab_size)
targets_idx = [word_to_idx[word] for word in targets]
inputs_one_hot = torch.from_numpy(inputs_one_hot)
inputs_one_hot = inputs_one_hot.permute(0, 2, 1)
targets_idx = torch.LongTensor(targets_idx)
#forward pass
outputs = net(inputs_one_hot)
#lossの計算
loss = criterion(outputs, targets_idx)
#backward pass 今はtrainingなので勾配を計算
loss.backward()
#LSTMのパラメータを更新
optimizer.step()
epoch_training_loss += loss.item()
writer.add_scalars("LSTM PyTorch Loss", {"val":epoch_validation_loss/len(validation_set), "train":epoch_training_loss/len(training_set)}, i)
writer.close()
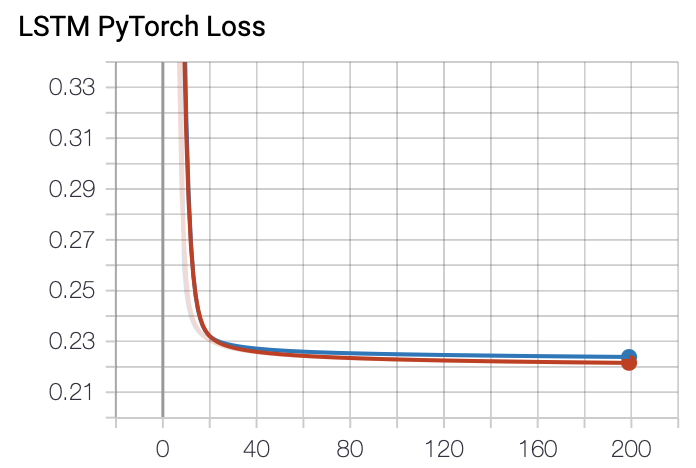
Lossのグラフです。綺麗にプロットできています。赤がtrain, 青がvalを表しています。 先ほどのnumpyで実装したLSTMより、ロスがしっかりと下がっています。フレームワークを使った方がよいですね。
まとめ
今回はRNNとLSTMを理解するために、numpyの実装をして軽い実験を行いました。また、PyTorchを用いてLSTMの実装を行いました。
参考文献
https://masamunetogetoge.com/gradient-vanish https://qiita.com/naoaki0802/items/7a11cded96f3a6165d01 http://kento1109.hatenablog.com/entry/2019/07/06/182247 https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca https://qiita.com/t_Signull/items/21b82be280b46f467d1b https://qiita.com/tanuk1647/items/276d2be36f5abb8ea52e