Understanding the Intuition Behind Mesh R-CNN
Objective
Understand Mesh R-CNN
Lv1. Understanding the intuition
Lv2. Network architecture
Lv3. Details such as loss functions
Prerequisites
ICCV 2019: Original paper available here
- GitHub repository: https://github.com/facebookresearch/meshrcnn
Overview
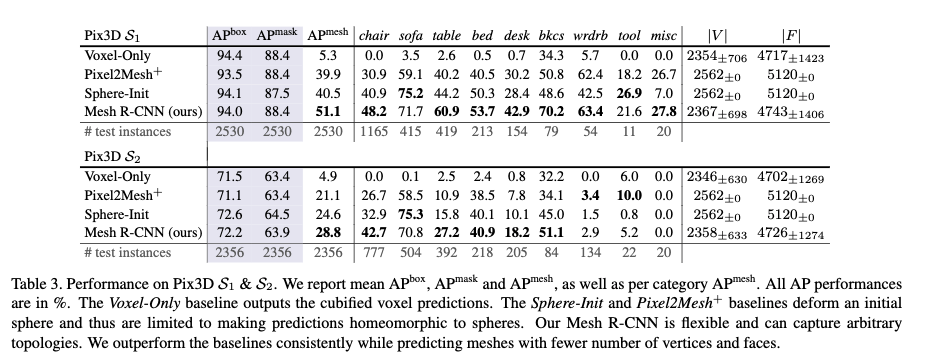
A method for obtaining meshes (3D shapes) from 2D images (shown below) End-to-end learning from input to output

Background (Related Work)
3D-related research has been active in recent years. Various techniques exist; representative related ones are briefly introduced below.
2D Object Recognition
Detects specific objects from a single input image. Typically outputs rectangular bounding box extraction and category labels. Mask R-CNN additionally extracts instance segmentation masks representing object regions.
Single-View Shape Prediction
Reconstructs 3D from a single image. Typically estimates 3D pose or orientation of known shapes.
Multi-View Shape Prediction
Performs 3D reconstruction from images captured by multiple cameras. Not addressed by Mesh R-CNN, but research in this area has been active in recent years.
3D Input
Tasks that take 3D images as input and output semantic labels, etc. Common inputs include RGB-D images and point clouds.
3D Dataset
ImageNet and the COCO dataset have driven significant advances in the 2D field. 3D datasets are still a developing area due to the difficulty of annotation compared to 2D. Various datasets such as ShapeNet, Pix3D, and Pascal3D have emerged, but many have dataset-specific issues such as being synthetic data or containing only bounding boxes without shape annotations.
Method
Lv1. Understanding the Intuition
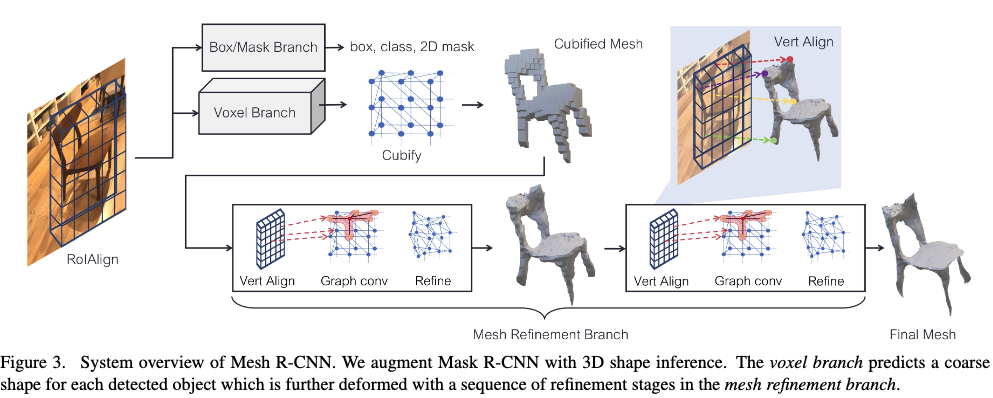
The overall architecture, as shown in the figure below, can be thought of as consisting of the following steps: Object detection --> Voxelization of the object --> Conversion to mesh --> Mesh refinement

Lv2. Explanation Including the Network
The detailed flow of the proposed system is shown in the figure below.
The general flow was explained in Lv1, but here we go into more detail.
First, the object detection component uses the conventional SoTA model Mask R-CNN --> Outputs category labels, bounding boxes, and segmentation masks The backbone is ResNet50 (pre-trained on ImageNet)
To predict 3D shapes, Voxel Branch and Mesh Refinement Branch are used.
As the names suggest:
- Voxel Branch .. Estimates a rough 3D voxelization of the object and converts it to an initial triangle mesh
- Mesh Refinement Branch .. Adjusts vertex positions of this initial mesh using graph convolution layers (refines the mesh)
-
Voxel Branch
- Predicts each object's shape in a bottom-up manner
- Conceptually similar to the mask branch of Mask R-CNN
- Predicts a 3D G x G x G shape from a 2D M x M input
- Loss is described later (in Lv3)
- (Note) Maintaining pixel-level correspondence between the image and predictions is complex in 3D because objects become smaller as they move away from the camera. To address this, the camera-specific intrinsic matrix is used to produce an idealized shape.
-
Cubify
- Voxel to Mesh
- The goal is to convert voxel predictions into a triangular mesh
- Takes voxel occupancy probabilities and a threshold for binarization as input
-
Mesh Refinement Branch
- The goal is to smooth the coarse shape (voxelization)
- The processing flow consists of three major components (vertex alignment, graph convolution, vertex refinement)
- Vertices are updated by iterating through these three steps
- At each layer, each mesh vertex holds a 3D position vi and a feature vector fi
- vertex alignment
- Generates image-aligned feature vectors for each mesh vertex
- Projects each vertex onto the image plane using the camera intrinsic matrix
- Given a feature map, computes bilinearly interpolated image features at the projected vertex positions
- graph convolution
-
Propagates information along mesh edges

-
Aggregates information from local mesh regions via GCN
-
- vertex refinement

- The mesh shape is updated and the topology is fixed
Lv3. Loss Function Design
Explains how the proposed system is optimized
-
Voxel Loss
- The Voxel Branch is trained to minimize the binary cross-entropy between predicted voxel occupancy probabilities and ground truth voxel occupancy
-
Mesh Loss
- Uses loss functions defined over finite point sets
- Represents meshes from point clouds by densely sampling their surfaces
- --> Approximates shape loss with point cloud loss
- Three main types of loss are defined:
- Chamfer Loss
- Given point clouds P and Q, defined by the following equation:

- Computes the distance to the nearest vertex
- Normal Loss
- Computes the inner product of normals up and uq

- Becomes small when point p and its adjacent vertices lie on the tangent plane of vertex q
- Edge Loss

- Computes and normalizes the distance between a vertex and its adjacent vertices
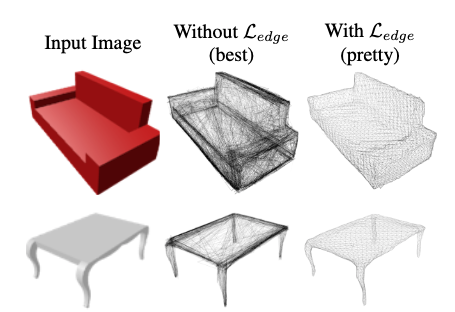
- (Note) A comparison of shapes with and without Edge Loss is shown below. Without it, the shapes are generated more cleanly, but there are concerns about practicality for applications due to irregularly sized faces and many self-intersections.
- The mesh refinement branch optimizes a weighted sum of the above three losses
Experiments
Training uses supervised learning with image-mesh pairs
Baseline Methods
-
N3MR ... Weakly supervised learning that trains meshes via a differentiable renderer without 3D supervision
-
3D-R2N2 ... Estimates voxels
-
MVD ... Estimates voxels
-
PSG ... Estimates point clouds
-
Pixel2Mesh ... Estimates meshes by deforming and subdividing an initial ellipsoid
-
GEOMetrics ... A model extending Pixel2Mesh with adaptive face subdivision
Note: voxel_only methods correspond to the proposed method without the Mesh Refinement Branch
mesh_only methods correspond to the proposed method without the Voxel Branch
Datasets (2 patterns)
ShapeNet ... A benchmark dataset for mesh prediction Pix3D dataset ... A more challenging dataset that includes real images
Evaluation Methods
10,000 points are randomly and uniformly sampled from the surfaces of both predicted and ground truth meshes --> Chamfer distance (lower is better), normal consistency, and F1-scores at various distance thresholds are computed for these point clouds (precision: ratio of predicted points within GT, recall: ratio of GT points within predictions) However, since these metrics depend on the absolute size of objects, evaluation is performed after rescaling.
ShapeNet Evaluation Results
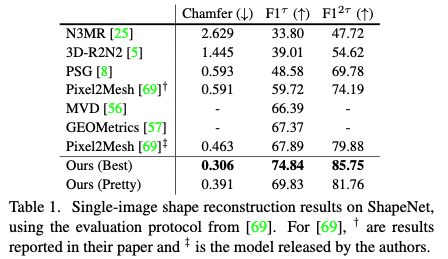
Pix3D Dataset Evaluation Results