On this page
One of the object detection models
High accuracy but slow speed
Used when speed is not required but accuracy is desired
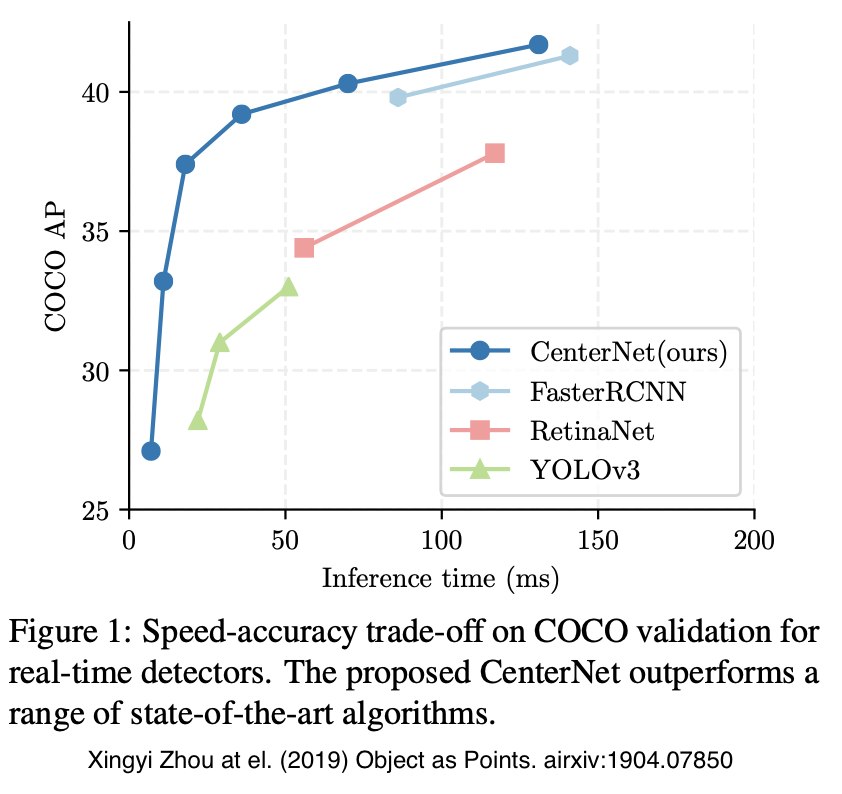
Comparison with Other Object Detection Models
Model Name Yolo v3 SSD Faster R-CNN CenterNet Accuracy Low Slightly low Slightly high High Speed Fast Slightly fast Slightly slow Slow
History
R-CNN
Detect approximately 2000 object-like regions using Selective Search
This part uses a hand-crafted algorithm
Identifies objects based on texture, color, etc.
Crop the detected regions, resize them to a fixed size, and extract features using a CNN
Classify with SVM and adjust BBOX positions with regression
Fast R-CNN
Problems with R-CNN
R-CNN requires training CNN, SVM, and BBOX regression separately
Slow execution time
Improvements
Introduced RoI pooling to eliminate redundant computations during Selective Search to CNN processing
Added a pooling layer with variable width after the CNN for feature extraction
This yields fixed-size feature vectors from inputs of varying sizes
Unified CNN, SVM, and BBOX regression into a single model
The overall flow remains the same as R-CNN
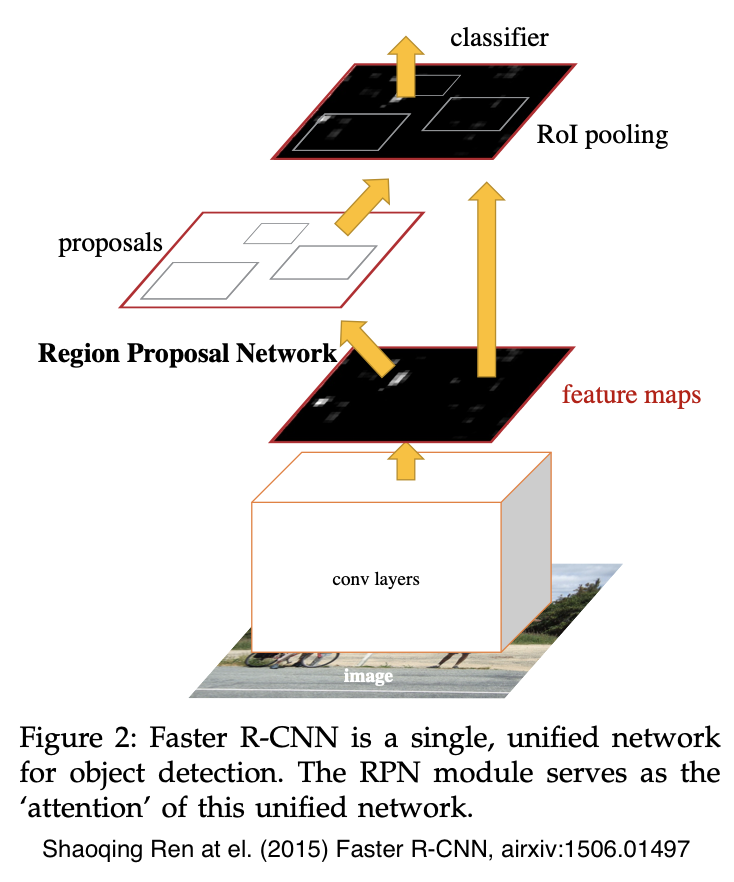
Faster R-CNN
Problems with Fast R-CNN
Selective Search is slow
Selective Search (region proposal) is not learned
Improvements
Replaced Selective Search with a Region Proposal Network
After applying a small CNN, features are extracted using AnchorBOXes (BBOXes) with different aspect ratios and sizes
Then, an FC layer performs regression for object/non-object classification and BBOX positions
Achieved speedup and higher accuracy through fully end-to-end learning
Similar Models (Details Omitted)
YOLO
Divides the image into a grid
Used for real-time applications
SSD
Uses features from different stages of convolution
Strong with low-resolution and small images
Cascade R-CNN
An improvement on Faster R-CNN
Gradually increases the IoU threshold
Good accuracy but demands significant computational resources
Model Architecture
Feed the image into convolutional layers to produce feature maps
image - conv_layers - feature_maps
Apply an nxn (n=3 in the paper) conv layer to the feature maps, then use FC-like conv layers (kernel=1, stride=1 to emulate fully connected behavior) to output objectness scores and positions (x1, x2, w, h)
Compute and classify BBOXes from the feature maps (step 1) and proposed regions (step 2)
Key Contributions in the Paper
In the RPN, training directly would be dominated by negative samples, so positive and negative samples are sampled at a 1:1 ratio
With the above model architecture, training produces an approximate solution rather than an exact one
This makes training faster
In the paper, the RPN and Fast R-CNN components were trained alternately
What Is CenterNet?
There are two models named CenterNet; this refers to the "Objects as Points" version
History
Heatmap-based methods
Came after Faster R-CNN and similar models
Use heatmaps instead of anchors
CornerNet (Aug 2018) is the origin
Instead of anchor-to-BBOX regression, it learns top-left and bottom-right keypoints via heatmaps
Model Architecture
Instead of anchors, predicts the center of objects per class using heatmaps
Properties such as height, width, and class are regressed at each position
Feed the image into a fully convolutional network to generate heatmaps
Identify heatmap peaks (compared against the surrounding 8 positions) as object centers
As needed, estimate object size, depth, orientation, pose, etc. from the feature vector at the object center