Video Vision Transformer
The Transformer, which swept through natural language processing achieving state-of-the-art results, has also been found to be a very powerful architecture in computer vision. If it can handle image recognition, then it should be able to handle video recognition too, right? That is what we investigated.
TL;DR
The current mainstream approaches for video recognition (primarily action recognition) are 3D CNNs and 2D LSTMs. However, since 3D CNNs can only model short-range dependencies, inference on long video clips had to be performed using short clips. This is counterintuitive, so a mechanism using Transformers was proposed to handle long sequence data.
On the other hand, processing long sequence data with a standard Transformer has the drawback of requiring very large computational resources.
To address this, the existing Longformer, which can efficiently process long texts, was leveraged to enable both reduced computation and learning from long clips.
Compared to SOTA methods, training speed was improved by 16.1x and inference speed by 5.1x while maintaining comparable accuracy.
Longformer (Long Document Processing Model)
A natural language processing model that reduced the Transformer's computational resource requirement from O(n^2) to O(n*w), making it applicable to long texts (w: window size).
It is equipped with two attention mechanisms to reduce computational resources.
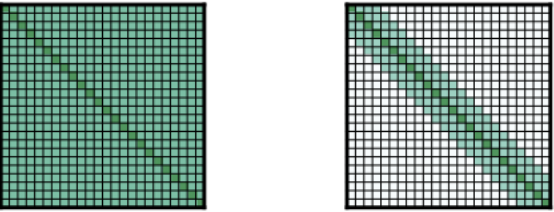

From left to right: Full n2 attention (standard attention), Sliding Window Attention, and Global+Sliding Attention.
-
Sliding window attention A structure that attends only to the immediate vicinity of each position. With a window size of w, attention is directed to 1/2w words on each side of the current position.
This reduces computational resources from O(n^2) to O(n*w).
Experiments showed that varying the window size per layer improves accuracy. Specifically, lower layers use smaller window sizes and upper layers use larger ones. This way, lower layers aggregate more local information while upper layers aggregate global information, leading to improved accuracy.
-
Global attention Used together with Sliding Window Attention. For words at specific positions, attention is directed to all words, and all words attend to those specific positions. In BERT, a [CLS] token is prepended to the first position and used for final classification, making the [CLS] token very important. Therefore, global attention is applied to the [CLS] token. The Video Transformer Network also applies global attention to the [CLS] token for the same reason.
Architecture
The overall architecture is shown below.
![vt_imgs/3.png]](/docs-imgs/論文解説/vt_imgs/3.png)
Components:
-
Spatial Backbone
The
f(x)part of the architecture that extracts spatial features from each frame. The module can be either a 2D CNN or a Transformer. In the ablation study, higher backbone performance led to higher action recognition accuracy. Also, fine-tuning outperformed using frozen weights. -
Temporal attention-based encoder
As described above, the Longformer is used. Specifically, spatial features extracted by the Spatial Backbone are passed through Positional Encoding before being input. Similar to BERT, a [CLS] token is prepended and used for the classification task.
In the ablation study, varying the depth of layers showed that deeper is not always better. This is reportedly because the videos in the dataset used were relatively short (around 10 seconds).
-
Classification MLP head A 2-layer MLP that takes the [CLS] token from the Temporal attention-based encoder as input. Outputs the classification result.
Ablation Experiments
Experiments were conducted on the Kinetics-400 dataset.
- Varying the number of frames and frame rate did not change accuracy.
- Regarding training and inference time, compared to SlowFast (a SOTA method), the model has more parameters but converges faster, achieving 16.1x speedup during training and 5.1x speedup during inference.
- Attention was qualitatively evaluated as follows. Since the weights on relevant regions were higher, attention was confirmed to be functioning properly.

(In a rappelling video, frames with similar content have higher weights.)